- 浏览器请求页面的不同方式
- Cache-Control与Expire比较
- DOCTYPE
- meat标签的http-equiv属性
- CSS选择器总结
- self=this
- 使用 [].slice.call将对象转换为数组的局限性
- 解决jQuery不同版本之间、与其他js库之间的冲突
- JavaScript中__proto__与prototype的关系
- JS中{}+[]和[]+{}的返回值
- js对象遍历顺序问题
- JSONP的原理理解
- AMD规范、requireJS理解
- call()、apply()
- 同源策略
- 浏览器沙箱
- 点击劫持(ClickJacking)
- HTML5带来的安全问题
- CSS盒模型
- 外边距叠加
- CSS可视化格式模型
- 匿名块框和匿名行框
- 相对定位、绝对定位、固定定位
- 浮动
- 行框和清理
- CSS链接伪类定义的顺序
- 为链接目标(同一页面的锚点)设置样式
- 为站点的所有下载.pdf文档的链接加上图标
- 3种CSS布局方式
- let定义变量的特性总结
- ES6一共有6种声明变量的方法
- 全局对象的属性
- 解构赋值
- 模板字符串
- 箭头函数
- 箭头函数没有自己的this
- 尾调用优化与尾递归
- 属性的遍历
- Symbol
- 二进制数组
- WeakSet与Set的区别
- WeakMap与Map的区别
- Iterator的遍历过程
- Generator函数与yield语句
- Generator与协程
- Promise对象
- 传值调用与传名调用
- async函数语法
- async函数对Generator函数的改进
- Class
- 类的prototype属性和__proto__属性
- Module
- 严格模式的限制
- ES6模块加载与CommonJS模块加载的区别
- 不同DOM级别的内容
- undefined值是派生自null值的
- 直接使用浮点数相等性比较的问题
- NaN、Infinity
- 是否所有类型的对象都可以通过调用toString()来将其转换为字符串?
- Object实例具有的属性和方法
- 使用for-in语句来枚举对象的属性
- label语句
- with语句
- arguments对象
- ECMAScript中支持函数重载吗?如果定义了同名的函数会怎样?
- 执行环境
- 作用域链
- 延长作用域链
- JavaScript是否有块级作用域?
- JavaScript的垃圾回收机制有哪些方式?如何优化JavaScript的内存占用?
- 在JavaScript中通过对象字面量方式定义对象与通过构造函数方式定义对象有什么不同?
- 在JavaScript中使用方括号表示法访问对象属性与使用点表示法访问对象属性有什么不同?
- 数组的length属性
- 使用instanceof操作符来判断一个变量是否是数组类型存在什么问题?如何解决?
- JavaScript原生的操作数组的方法
- 定义JavaScript函数的方式
- JavaScript函数拥有的属性和方法
- 基本包装类型
- 为什么说Boolean 对象在 ECMAScript 中的用处不大?
- String类型的实例的属性和方法
- Global对象的属性和方法
- Global对象与Windows对象有什么区别?
- 什么是attribute?与property有什么关系?有哪些attribute?有哪些property?
- 有哪些创建JavaScript对象的模式?各有什么利弊?
- 构造函数、构造函数的原型对象以及构造函数的实例,相互之间是什么关系?
- 如何判断对象属性的定义位置?
- 基于原型链实现继承的原理是什么?存在什么问题?
- JavaScript中有哪些实现继承的方式?
- 什么是闭包?闭包的实现原理是什么?存在什么问题?
- 匿名函数的中的this指向哪里?
- 如何使用匿名函数来模仿块级作用域?
- JavaScript中的DOM节点有哪些类型?DOM节点有哪些属性和方法?
- document对象的类型是什么?有哪些属性和方法?
- 有哪些对DOM的扩展?
- 有哪些为元素定义事件的方式?
- event对象有哪些属性和方法?currentTarget和target有什么区别?
- 如何优化因为定义事件而带来的性能问题?
- 如何触发模拟事件?如何自定义事件?
- 有哪些提交表单、重置表单的方式?
- 在表单提交时,浏览器是怎样组织数据并发送给服务器的?
- 富文本编辑的原理是什么?
- Ajax和Comet的区别是什么?Comet有哪些实现方式?
- Websocket的建立流程是怎样的?它有哪些优缺点?
- 什么是SSE?如何选择应该是用SSE还是Web Socket?
- 如何区分原生与非原生JavaScript对象?
- 如何定义作用域安全的构造函数?
- 如何阻止向对象中添加属性和方法?
- 什么是密封对象?它有哪些特性?
- 什么是冻结对象?它有哪些特性?
- JavaScript中的定时器是基于线程实现的吗?
- 什么是Yielding Processes?
- 什么是函数节流?它通常应用在什么场景中?
- 如何实现自定义事件管理框架?
- ES6新语法
- ES6与ES5,this的变化比较
- js类静态部分与实例部分的区别(参考typescript文档 类类型)
- js内存泄漏是怎么产生的?
- 什么是闭包,跟原型链、作用域链有什么关联
- npm模块安装机制
- 容器的水平居中
- 文字的垂直居中
- 容器的垂直居中
- 图片宽度的自适应
- link状态的设置顺序
- 用图片充当列表标志
浏览器请求页面的不同方式
- Ctrl+F5:强制刷新,使网页中所有组件都直接向Web服务器发送请求,并且不使用缓存协商。
- F5:等同于浏览器的刷新按钮,允许浏览器在请求中附加必要的缓存协商,但不允许浏览器直接使用本地缓存,即可以使用Last-Modified,但Expires无效。
- 在浏览器地址栏输入URL后回车,或者通过超链接跳转到该页面 浏览器会对所有没有过期的内容直接使用本地缓存。
Cache-Control与Expire比较
Expire使用的是绝对过期时间,存在一些不足之处,比如浏览器和服务器的时间不一致。 HTTP/1.1提供Cache-Control,使用相对时间来弥补Expires的不足,格式如下:
Cache-Control:max-age=<second>
目前主流的浏览器都将HTTP/1.1作为首选,所以当HTTP响应头中同时含有Expires和Cache-Control时,浏览器会优先考虑Cache-Control。
DOCTYPE
<!DOCTYPE> 声明不是HTML标签;它是指示web浏览器关于页面使用哪个HTML版本进行编写的指令。必须是HTML文档的第一行,位于<html>标签之前。没有结束标签。对大小写不敏感。
在HTML 4.01中有三种<!DOCTYPE>声明。在HTML5中只有一种:<!DOCTYPE html>
应该始终向HTML文档添加<!DOCTYPE>声明,这样浏览器才能获知文档类型。
meat标签的http-equiv属性
http-equiv属性可用于模拟一个HTTP响应头。
// 设定网页的到期时间(一旦网页过期,必须到服务器上重新传输)
<meta http-equiv="expires" content="Wed, 20 Jun 2007 22:33:00 GMT">
// 禁止浏览器从本地机的缓存中调阅页面内容(这样设定,访问者将无法脱机浏览)
<meta http-equiv="Pragma" content="no-cache">
// 自动刷新并指向新页面(停留2秒钟后自动刷新到URL网址)
<meta http-equiv="Refresh" content="2; URL=http://www.net.cn/">
// 设置Cookie(如果网页过期,那么存盘的cookie将被删除)
<meta http-equiv="Set-Cookie" content="cookievalue=xxx;expires=Wednesday, 20-Jun-2007 22:33:00 GMT;path=/">
// 显示窗口的设定(强制页面在当前窗口以独立页面显示,防止别人在框架里调用自己的页面)
<meta http-equiv="Window-target" content="_top">
// 设定页面使用的字符集
<meta http-equiv="Content-Type" content="text/html; charset=gb2312">
// 网页等级评定
<meta http-equiv="Pics-label" contect="">
在IE的internet选项中有一项内容设置,可以防止浏览一些受限制的网站,而网站的限制级别就是通过meta属性来设置的。
// 设定进入页面时的特殊效果
<meta http-equiv="Page-Enter" contect="revealTrans(duration=1.0,transtion=12)">
// 设定离开页面时的特殊效果
<meta http-equiv="Page-Exit" contect="revealTrans(duration=1.0,transtion=12)">
// 清除缓存
<meta http-equiv="cache-control" content="no-cache">
// 关键字,给搜索引擎用的
<meta http-equiv="keywords" content="keyword1,keyword2,keyword3">
// 页面描述,给搜索引擎用的
<meta http-equiv="description" content="This is my page">
CSS选择器总结
- 类型选择器、元素选择器、简单选择器
p {color:black;} - 后代选择器
blockquote p{color:black;} - ID选择器
#intro{color:black;} - 类选择器
.intro{color:black;} - 伪类
根据文档结构之外的其他条件对元素应用样式,例如表单元素或链接的状态
tr:hover{background-color:red;} input:focus{background-color:red;} a:hover,a:focus,a:active{color:red;}:link和:visited称为链接伪类,只能应用于锚元素。:hover、:active和:focus称为动态伪类,理论上可以应用于任何元素。 可以把伪类连接在一起,创建更复杂的行为:
a:visited:hover{color:red;} - 通用选择器
匹配所有可用元素
*{ padding:0; margin:0; }通用选择器与其他选择器结合使用时,可以用来对某个元素的所有后代应用样式。
- 子选择器
只选择元素的直接后代,而不是像后代选择器一样选择元素的所有后代。
#nav>li{ padding-left:20px; color:red; } - 相邻同胞选择器
用于定位同一个父元素下与某个元素相邻的下一个元素。
h2 + p{ font-size:1.4em; } - 属性选择器 根据某个属性是否存在或者属性的值来寻找元素。
abbr[title]{
border-bottom:1px dotted #999;
}
abbr[title]:hover{
cursor:help;
}
a[rel=’nofollow’]{
color:red;
}
注意:属性名无引号,属性值有引号。
对于属性可以有多个值的情况(空格分割),属性选择器允许根据属性值之一来寻找元素:
.blogroll a[rel~=’co-worker’]{...}
self=this
This question is not specific to jQuery, but specific to JavaScript in general. The core problem is how to "channel" a variable in embedded functions. This is the example:
var abc = 1; // we want to use this variable in embedded functions
function xyz(){
console.log(abc); // it is available here!
function qwe(){
console.log(abc); // it is available here too!
}
...
};
This technique relies on using a closure. But it doesn’t work with this because this is a pseudo variable that may change from scope to scope dynamically:
// we want to use "this" variable in embedded functions
function xyz(){
// "this" is different here!
console.log(this); // not what we wanted!
function qwe(){
// "this" is different here too!
console.log(this); // not what we wanted!
}
...
};
What can we do? Assign it to some variable and use it through the alias:
var self = this; // we want to use this variable in embedded functions
function xyz(){
// "this" is different here! --- but we don't care!
console.log(self); // now it is the right object!
function qwe(){
// "this" is different here too! --- but we don't care!
console.log(self); // it is the right object here too!
}
...
};
this is not unique in this respect: arguments is the other pseudo variable that should be treated the same way — by aliasing.
使用 [].slice.call将对象转换为数组的局限性
var arrayLike = {
'0': 'a',
'1': 'b',
'2': 'c',
length: 3
};
var arr = [].slice.call(arrayLike);
console.log(arr); // ["a", "b", "c"]
被转换为数组的对象必须有length属性,所谓类似数组的对象,本质特征只有一点,即必须有length属性。
var arrayLike = {
'0': 'a',
'1': 'b',
'2': 'c'
};
var arr = [].slice.call(arrayLike);
console.log(arr); // []
解决jQuery不同版本之间、与其他js库之间的冲突
- 同一页面jQuery多个版本或冲突解决方法
<html lang="en" xmlns="http://www.w3.org/1999/xhtml">
<head>
</head>
<body>
<!-- 引入 jquery 1.8.0 -->
<script type="text/javascript" src="http://code.jquery.com/jquery-1.8.0.min.js"></script>
<script type="text/javascript">
var $180 = $;
</script>
<!-- 引入 jquery 1.9.0 -->
<script type="text/javascript" src="http://code.jquery.com/jquery-1.9.0.min.js"></script>
<script type="text/javascript">
var $190 = $;
</script>
<!-- 引入 jquery 2.0.0 -->
<script type="text/javascript" src="http://code.jquery.com/jquery-2.0.0.min.js"></script>
<script type="text/javascript">
var $200 = $;
</script>
<script type="text/javascript">
console.log($180.fn.jquery);
console.log($190.fn.jquery);
console.log($200.fn.jquery);
</script>
</body>
</html>
- 同一页面jQuery和其他js库冲突解决方法 1)jQuery在其他js库之前 ```javascript
2)jQuery在其他js库后
```javascript
<html lang="en" xmlns="http://www.w3.org/1999/xhtml">
<head>
</head>
<body>
<!-- 引入 其他库-->
<script type="text/javascript">
$ = {
fn:{
jquery:"111cn.net"
}
};
</script>
<!-- 引入 jquery 1.8.0 -->
<script type="text/javascript" src="http://code.jquery.com/jquery-1.8.0.min.js"></script>
<script type="text/javascript">
console.log($.fn.jquery); # 1.8.0
var $180 = $.noConflict();
console.log($.fn.jquery); # 111cn.net
console.log($180.fn.jquery); # 1.8.0
</script>
</body>
</html>
JavaScript中__proto__与prototype的关系
__proto__ 对象的内部原型
prototype 构造函数的原型
- 所有函数/构造函数(包括内置的、自定义的)的
__proto__都指向Function.prototype,它是一个空函数(Empty function)Number.__proto__ === Function.prototype // true
Global对象的__proto__不能直接访问;
Arguments对象仅在函数调用时由JS引擎创建;
Math,JSON是以对象形式存在的,无需new,它们的__proto__是Object.prototype:
JSON.__proto__ === Object.prototype // true
-
构造函数都来自于Function.prototype,包括Object及Function自身,因此都继承了Function.prototype的属性及方法。如length、call、apply、bind等。
- Function.prototype也是唯一一个typeof XXX.prototype为 “function”的prototype。其它的构造器的prototype都是一个对象:
console.log(typeof Function.prototype) // function 一个空函数 console.log(typeof Object.prototype) // object console.log(typeof Number.prototype) // object - Function.prototype的__proto__等于Object的prototype:
console.log(Function.prototype.__proto__ === Object.prototype) // true 体现了在Javascript中`函数也是一等公民` - Object.prototype的__proto__为null
Object.prototype.__proto__ === null // true 到顶了 - 所有对象的__proto__都指向其构造器的prototype
var obj = {name: 'jack'}
var arr = [1,2,3]
var reg = /hello/g
console.log(obj.__proto__ === Object.prototype) // true
console.log(arr.__proto__ === Array.prototype) // true
console.log(reg.__proto__ === RegExp.prototype) // true
function Person(name) {
this.name = name
}
var p = new Person('jack')
console.log(p.__proto__ === Person.prototype) // true
```
* 每个对象都有一个`constructor属性`,可以获取它的构造器
```
function Person(name) {
this.name = name
}
Person.prototype.getName = function() {} // 修改原型
var p = new Person('jack')
console.log(p.__proto__ === Person.prototype) // true
console.log(p.__proto__ === p.constructor.prototype) // true
- 使用对象字面量方式定义对象的构造函数,则对象的constructor的prototype可能不等于对象的__proto__
function Person(name) {
this.name = name
}
// 使用对象字面量方式定义的对象其constructor指向Object,Object.prototype是一个空对象{}
Person.prototype = {
getName: function() {}
}
var p = new Person('jack')
console.log(p.__proto__ === Person.prototype) // true
console.log(p.__proto__ === p.constructor.prototype) // false
JS中{}+[]和[]+{}的返回值
[] + {} 。一个数组加一个对象。 加法会进行隐式类型转换,规则是调用其 valueOf() 或 toString() 以取得一个非对象的值(primitive value)。如果两个值中的任何一个是字符串,则进行字符串串接,否则进行数字加法。 [] 和 {} 的 valueOf() 都返回对象自身,所以都会调用 toString(),最后的结果是字符串串接。[].toString() 返回空字符串,({}).toString() 返回“[object Object]”。最后的结果就是“[object Object]”。
{} + [] 。看上去应该和上面一样。但是 {} 除了表示一个对象之外,也可以表示一个空的 block。在 [] + {} 中,[] 被解析为数组,因此后续的 + 被解析为加法运算符,而 {} 就解析为对象。但在 {} + [] 中,{} 被解析为空的 block,随后的 + 被解析为正号运算符。即实际上成了:
{ // empty block }
+[]
即对一个空数组执行正号运算,实际上就是把数组转型为数字。首先调用 [].valueOf() 。返回数组自身,不是primitive value,因此继续调用 [].toString() ,返回空字符串。空字符串转型为数字,返回0,即最后的结果。
js对象遍历顺序问题
var a = {
b:'a',
10: "vv",
1:"a",
a:''
}
console.log(a);
Object: 1:”a” 10:”vv” a:”” b:”a”
JSONP的原理理解
JSONP是一种解决跨域传输JSON数据的问题的解决方案,是一种非官方跨域数据交互协议。 Ajax(或者说js)直接请求普通文件存在跨域无权限访问的问题,但是Web页面上凡是拥有"src"属性的标签引用文件时则不受是否跨域的影响。如果想通过纯web端(ActiveX控件、服务端代理、Websocket等方式不算)跨域访问数据就只有一种可能:在远程服务器上设法把数据装进js格式的文件里,供客户端调用和进一步处理。 为了便于客户端使用数据,逐渐形成了一种非正式传输协议:JSONP,该协议的一个要点就是允许用户传递一个callback参数给服务端,然后服务端返回数据时会将这个callback参数作为函数名来包裹住JSON数据,这样客户端就可以随意定制自己的函数来自动处理返回数据了。
例:使用Javascript实现JSONP
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title></title>
<script type="text/javascript">
// 回调函数
var flightHandler = function(data){
alert('你查询的航班结果是:票价 ' + data.price + ' 元,' + '余票 ' + data.tickets + ' 张。');
};
// 拼凑url
var url = "http://flightQuery.com/jsonp/flightResult.aspx?code=CA1998&callback=flightHandler";
// 拼凑<script>标签,用于发出JSONP请求
var script = document.createElement('script');
script.setAttribute('src', url);
document.getElementsByTagName('head')[0].appendChild(script);
</script>
</head>
<body>
</body>
</html>
服务器端返回格式:
flightHandler({
"code": "CA1998",
"price": 1780,
"tickets": 5
});
例:使用jQuery实现JSONP
<script type="text/javascript" src=jquery.min.js"></script>
<script type="text/javascript">
jQuery(document).ready(function(){
$.ajax({
type: "get",
async: false,
url: "http://flightQuery.com/jsonp/flightResult.aspx?code=CA1998",
dataType: "jsonp",
jsonp: "callback", // 传递给请求处理程序或页面的,用以获得jsonp回调函数名的参数名(一般默认为:callback)
jsonpCallback:"flightHandler", // 自定义的jsonp回调函数名称,没有定义的话会jQuery会自动生成以jQuery开头的函数
success: function(json){
alert('您查询到航班信息:票价: ' + json.price + ' 元,余票: ' + json.tickets + ' 张。');
},
error: function(){
alert('fail');
}
});
});
</script>
jquery在处理jsonp类型的ajax时自动生成回调函数并把数据(即不含函数名的纯json格式的数据)取出来供success属性方法来调用。
AMD规范、requireJS理解
AMD规范:Asynchronous Module Definition,即异步模块加载机制。AMD规范简单到只有一个API,即define函数:
define([module-name?], [array-of-dependencies?], [module-factory-or-object]);
- module-name: 模块标识,可以省略。
- array-of-dependencies: 所依赖的模块,可以省略。
- module-factory-or-object: 模块的实现,或者一个JavaScript对象。
当define函数执行时,它首先会异步地去调用第二个参数中列出的依赖模块,当所有的模块被载入完成之后,如果第三个参数是一个回调函数则执行,然后告诉系统模块可用,也就通知了依赖于自己的模块自己已经可用。
实例:
define("alpha", ["require", "exports", "beta"], function (require, exports, beta) { // 依赖的模块做参数传入 exports.verb = function() { return beta.verb(); } });requireJS例一:使用requirejs动态加载jquery 目录结构:
/web /index.html # 页面文件 /jquery-1.7.2.js # jquery模块 /main.js # js加载主入口,在引用require.js文件时通过data-main属性指定 /require.js # requireJS文件index.html文件内容: ```html <!doctype html>
main.js文件内容:
```javascript
require.config({
paths: {
jquery: 'jquery-1.7.2'
}
});
require(['jquery'], function($) {
alert($().jquery);
});
引用模块jquery,因为这里配置了jquery的paths参数,所以将使用参数所对应的值’jquery-1.7.2’(js后缀名省略)。 jQuery从1.7以后支持AMD规范,所以当jQuery作为一个AMD模块运行时,它的模块名是jquery(区分大小写)。 如果文件名’jquery-1.7.2’改为jquery,则无需配置path参数。
requireJS例二:使用自定义模块 目录结构:
/web
/js
/cache.js # 自定义模块
/event.js # 自定义模块
/main.js
/selector.js # 自定义模块
/index.html
/require.js
index.html文件内容:
<html>
<head>
<meta charset="utf-8">
<style type="text/css">
p {
width: 200px;
background: gray;
}
</style>
</head>
<body>
<p>p1</p><p>p2</p><p>p3</p><p>p4</p><p>p5</p>
<script data-main="js/main" src="require.js"></script>
</body>
</html>
cache模块内容:返回一个js对象
define(function() {
...
return {
set: function(el, key, val) {
var c = ...;
...
return c;
},
...
};
});
event模块内容:依赖于cache模块(define第一个参数为依赖的模块列表,第二个参数为一个函数,函数形参直接使用模块)
define(['cache'], function(cache) {
...
return { # 返回一个js对象
bind : bind,
unbind : unbind,
trigger : trigger
};
});
selector模块内容:
define(function() {
function query(selector,context) {
...
}
return query; # 返回一个js函数
});
main.js内容:
require.config({
baseUrl: 'js'
});
require(['selector', 'event'], function($, E) { # 函数两个形参一一对应所依赖的两个模块
var els = $('p');
for (var i=0; i < els.length; i++) {
E.bind(els[i], 'click', function() {
alert(this.innerHTML);
});
}
});
call()、apply()
call和apply都是为了改变某个函数运行时的context即上下文而存在的,换句话说,就是为了改变函数体内部this的指向。因为JavaScript的函数存在定义时上下文和运行时上下文以及上下文是可以改变的这样的概念。
二者的作用完全一样,只是接受参数的方式不太一样。例如,有一个函数 func1 定义如下:
var func1 = function(arg1, arg2) {};
就可以通过 func1.call(this, arg1, arg2); 或者 func1.apply(this, [arg1, arg2]); 来调用。其中 this 是你想指定的上下文,他可以任何一个 JavaScript 对象(JavaScript 中一切皆对象),call 需要把参数按顺序传递进去,而 apply 则是把参数放在数组里。
JavaScript 中,某个函数的参数数量是不固定的,因此要说适用条件的话,当你的参数是明确知道数量时,用 call,而不确定的时候,用 apply,然后把参数 push 进数组传递进去。当参数数量不确定时,函数内部也可以通过 arguments 这个数组来便利所有的参数。
call和apply是为了动态改变this而出现的,当一个object没有某个方法,但是其他的有,我们可以借助call或apply用其它对象的方法来操作。
同源策略
同源策略是浏览器最核心、最基本的安全功能。影响源的因素包括:host(或IP)、子域名、端口、协议; 注意:对于当前页面,页面内JavaScript文件自身的域并不重要,重要的是加载JavaScript的页面所在的域。
<script>、<img>、<iframe>、<link>等带src属性的标签可以跨域加载资源,每次加载实际上是由浏览器发起了一次GET请求。不同于XMLHttpRequest的是,通过src属性加载的资源被JavaScript限制了权限:不能读、写返回的内容。XMLHttpRequest可以访问来自同源对象的内容。W3C同时也制定了XMLHttpRequest跨域访问的标准:通过目标域返回的HTTP头来授权是否允许跨域访问(Access-Control-Allow-Origin)。这个跨域访问方案的安全基础基于“JavaScript无法控制该HTTP头”。
浏览器沙箱
现代的浏览器采用多进程架构来将各个功能模块分开,渲染引擎由Sandbox隔离,网页代码要与浏览器内核进程通信、与操作系统通信都需要经过IPC channel,而在其中会进行一些安全检查。Sandbox的设计目的就是为了让不可信任的代码运行在一定的环境中,限制不可信任的代码访问隔离区之外的资源,要跨越Sandbox边界产生数据交换只能经由指定的数据通道(封装的API)。
点击劫持(ClickJacking)
点击劫持是一种视觉上的欺骗手段,比如使用一个透明的iframe覆盖在一个网页上,然后诱使用户在该网页上进行操作,通过调整iframe页面的位置,可以使得用户恰好点击在iframe页面的一些功能性按钮上。 图片覆盖是另一种类似的视觉欺骗的方法。
防御ClickJacking
- 1.frame busting:通过写一段JavaScript代码禁止iframe的嵌套;(由于使用JavaScript,因此控制能力并不是特别强,有很多方法可以绕过它)
- 2.X-Frame-Options 当值为DENY时浏览器会拒绝当前页面加载任何frame页面,为SAMEORIGIN时可以加载同源下的页面,当值为ALLOW-FROM,可以定义运行的页面。
HTML5带来的安全问题
-
新标签的XSS
<video>、<audio>等,可能绕过站点现有的XSS Filter。 -
iframe的sandbox属性 iframe被新增一个sandbox属性,使用这个属性后加载的内容将被视为一个独立的源,其中的脚本将被禁止执行,表单被禁止提交,插件被禁止加载,指向其他浏览器对象的链接也会被禁止。
<iframe sandbox="allow-same-origin allow-forms allow-scripts" src="..." ></iframe>
- noreferrer
<a>和<area>标签定义了新的名为noreferrer的Link Types,标签指定该值后,浏览器在请求该标签指定的地址时将不再发送Referer:
<a href="xxx" rel="noreferrer">test</a>
-
Canvas 利用Canvas可以识别简单的图片验证码。
-
postMessage HTML5中新的API,运行每一个window对象往其他的窗口发送文本消息,从而实现跨窗口的消息传递,且这个功能不受同源策略限制,因此需要自己做安全判断。
-
Web Storage Web Storage分为Session Storage和Local Storage,前者在关闭浏览器时就会失效,后者会一直存在。Web Storage也受到同源策略的约束。 当Web Storage中保存敏感信息时,也会成为XSS的攻击目标。
CSS盒模型
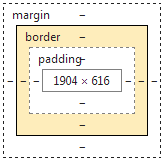
- 1.由内到外为:内容-内边距-边框-外边距。
- 2.如果在元素上添加背景,那么背景会被应用于由内容和内边距组成的区域。外边距是透明的,一般用来控制元素之间的间隔。
- 3.此外CSS2.1还支持outline属性,与border不同的是其将轮廓绘制在元素框上。
- 4.内边距、边框、外边距都是可选的,默认值为0,但是许多元素会被浏览器设置外边距和内边距,可以通过如下方式重置:
*{ margin:0; padding:0; } - 5.但是这种方式不区分元素,可能会对如option等元素造成不利影响,因此使用全局reset把内边距和外边距显式地设置为0可能更安全。
- 6.width和height指的是内容区域的宽度和高度,增加内边距、边框和外边距不会影响内容区域的尺寸,但是会增加元素框的总尺寸。
- 7.内边距、边框、外边距可以应用于一个元素的所有边,也可以应用于单独的边。外边距还可以是负值。
外边距叠加
- 1.当两个或更多个垂直外边距相遇时,它们将合并为一个外边距,这个新外边距的高度等于两个发生叠加的外边距的高度中的较大者。
- 2.当一个元素包含在另一个元素中时,如果没有内边距或者边框将外边距分隔开,那么它们的顶、底外边距也会发生叠加。
- 3.甚至同一个元素,如果没有内边距、边框以及内容,此时它的顶外边距与底外边距碰在一起,也会发生叠加。而且如果这个新的外边距碰到了另一个元素的外边距,它还会发生叠加。 注意:只有普通文档流中块框的垂直外边距才会发生外边距叠加。行内框、浮动框或者绝对定位框之间的外边距不会叠加。
CSS可视化格式模型
- 1.块级元素:显示为一块内容,即块框,如p、h1、div等。
- 2.行内元素:内容显示在行中,即行内框,如strong、span等。
- 3.可以使用display属性来改变生成的框的类型,如将a标签的display设置为block,从而让其表现的像块级元素一样;还可以设置display属性为none,让生成的元素根本没有框,不占用文档中的空间。
- 4.CSS中有3种基本的定位机制:普通流、浮动、绝对定位。
- 5.块级框从上到下一个接一个地垂直排列,框之间的垂直距离由框的垂直外边距计算出来。
- 6.行内框在一行中水平排列。可以使用水平内边距、边框、外边距来调整它们的水平间距,但是行内框的垂直内边距、边框和外边距不会增加行高,设置显式的高度或宽度也不行。由一行形成的水平框称为行框,行框高度等于本行内所有元素中行高最大的值,可以通过设置行高(line-height)来修改这个高度。CSS2.1支持将display属性设置为inline-block,这将使元素像行内元素一样水平地依次排列,但是框的内容仍然符合块级框的行为,如能够显式地设置宽度、高度、垂直外边距和内边距。
匿名块框和匿名行框
- 匿名块框:当将文本添加到一个块级元素的开头时,即使没有把这些文本定义为块级元素,它也会被当成块级元素对待:
<div>
some text
<p>other text</p>
</div>
- 匿名行框:块级元素内的文本,每一行都会形成匿名行框。无法直接对匿名块或者行框应用样式,除非使用:first-line伪元素。
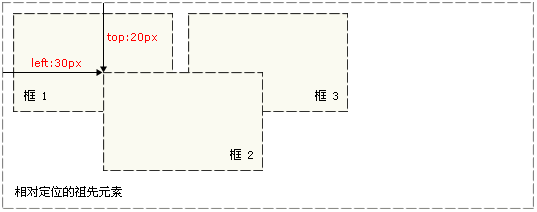
相对定位、绝对定位、固定定位
- 相对定位:如果对一个元素进行相对定位,它将出现在它所在的位置上,然后可以通过设置top、left等属性让这个元素相对于它的起点移动。无论是否移动,元素仍然占据原来的空间,因此移动元素会导致它覆盖其他框。相对定位实际上是普通流定位模型的一部分。
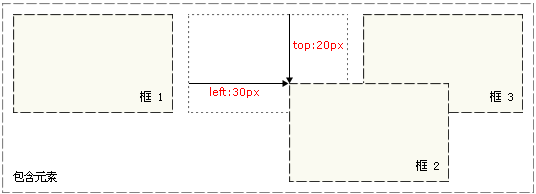
- 绝对定位:绝对定位的元素的位置是相对于距离它最近的那个已定位的祖先元素确定的,如果没有已定位的祖先元素,那么它的位置是相对于初始包含块的。元素定位后生成一个块级框,而不论原来它在正常流中生成何种类型的框。绝对定位使元素的位置与文档流无关。
- 固定定位:相对于viewport进行定位。
浮动
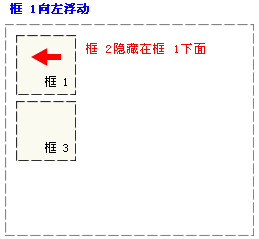
浮动的框可以左右移动,直到它的外边缘碰到包含框或另一个浮动框的边缘。浮动框不在文档的普通流中。
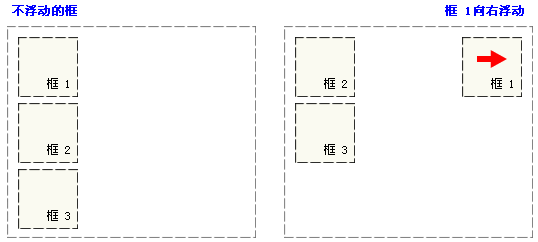 当框 1 向左浮动时,它脱离文档流并且向左移动,直到它的左边缘碰到包含框的左边缘。因为它不再处于文档流中,所以它不占据空间,实际上覆盖住了框 2,使框 2 从视图中消失:
当框 1 向左浮动时,它脱离文档流并且向左移动,直到它的左边缘碰到包含框的左边缘。因为它不再处于文档流中,所以它不占据空间,实际上覆盖住了框 2,使框 2 从视图中消失:
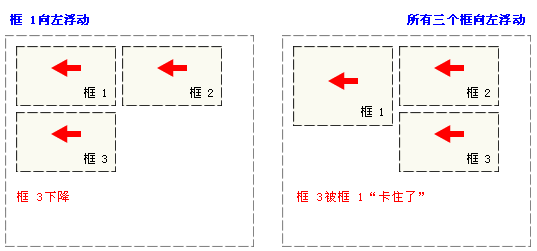
 如果包含框太窄,无法容纳水平排列的三个浮动元素,那么其它浮动块向下移动,直到有足够的空间。如果浮动元素的高度不同,那么当它们向下移动时可能被其它浮动元素“卡住”:
如果包含框太窄,无法容纳水平排列的三个浮动元素,那么其它浮动块向下移动,直到有足够的空间。如果浮动元素的高度不同,那么当它们向下移动时可能被其它浮动元素“卡住”:
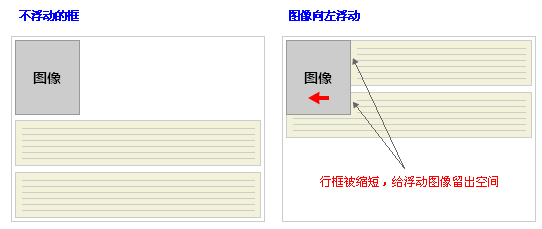
行框和清理
浮动框旁边的行框被缩短,从而给浮动框留出空间,行框围绕浮动框。
因此,创建浮动框可以使文本围绕图像:
 要想阻止行框围绕浮动框,需要对该框应用clear属性。clear 属性定义了元素的哪边上不允许出现浮动元素。在 CSS1 和 CSS2 中,这是通过自动为清除元素(即设置了clear属性的元素)增加上外边距实现的。在 CSS2.1 中,会在元素上外边距之上增加清除空间,而外边距本身并不改变。不论哪一种改变,最终结果都一样,如果声明为左边或右边清除,会使元素的上外边框边界刚好在该边上浮动元素的下外边距边界之下。(即浏览器会自动添加上外边距)
要想阻止行框围绕浮动框,需要对该框应用clear属性。clear 属性定义了元素的哪边上不允许出现浮动元素。在 CSS1 和 CSS2 中,这是通过自动为清除元素(即设置了clear属性的元素)增加上外边距实现的。在 CSS2.1 中,会在元素上外边距之上增加清除空间,而外边距本身并不改变。不论哪一种改变,最终结果都一样,如果声明为左边或右边清除,会使元素的上外边框边界刚好在该边上浮动元素的下外边距边界之下。(即浏览器会自动添加上外边距)

CSS链接伪类定义的顺序
选择器的次序很重要,如果定义顺序反过来:
a:hover,a:focus,a:active{text-decoration:underline;}
a:link, a:visited {text-decoration:none;}
则鼠标悬停和激活的样式就不起作用了。这是因为两个规则具有相同的特殊性,所以a:link, a:visited将覆盖a:hover,a:focus,a:active。最好按如下顺序进行定义:
a:link、a:visited、a:hover、a:focus、a:active
为链接目标(同一页面的锚点)设置样式
:target
{
border: 2px solid #D4D4D4;
background-image: url(img/fade.gif); /* 设置一个黄色渐变为白色的动画图片 */
}
/* 在站点的所有外部链接的右上角显示一个图标 */
a[href^=’http:’]{ /* 使用属性选择器 */
background:url(/img/external.gif) no-repeat right top;
padding-right:10px;
}
a[href^=’http://www.mysite.com’]{ /* 覆盖排除本站点的绝对链接 */
background:none;
padding-right:0;
}
为站点的所有下载.pdf文档的链接加上图标
a[href$=’.pdf’]{
background:url(img/pdf.gif) no-repeat right top;
padding-right:10px;
}
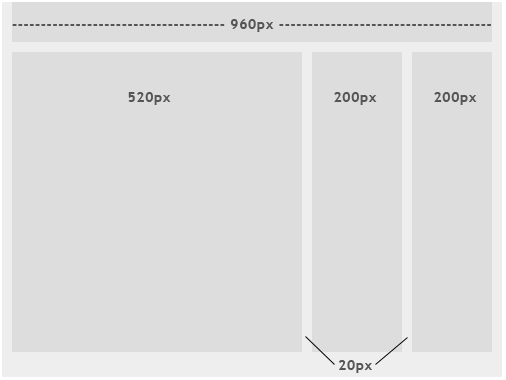
3种CSS布局方式
所有CSS布局技术的根本都是3个基本概念:定位、浮动、外边距操作。
- 固定布局:
- 流式布局:
- 弹性布局:相当于以上两者的结合。其要点就在于使用单位em来定义元素宽度。em是相对长度单位。相对于当前对象内文本的字体尺寸。如当前对行内文本的字体尺寸未被人为设置,则相对于浏览器的默认字体尺寸。任意浏览器的默认字体高都是16px,所有未经调整的浏览器都符合: 1em=16px。
let定义变量的特性总结
- 使用let声明的变量只在let命令所在的代码块内有效;
- 使用let声明的变量不会“变量提升”,变量一定要在声明后使用;
- 只要块级作用域内存在let命令,它所声明的变量就“绑定”(binding)这个区域,不再受外部的影响(const同理);
- let不允许在相同作用域内,重复声明同一个变量;
- let为JavaScript新增了块级作用域,使得获得广泛应用的立即执行匿名函数(IIFE)不再必要了;
ES6一共有6种声明变量的方法
- var
- function
- let
- const
- import
- class
全局对象的属性
全局对象是最顶层的对象,在浏览器环境指的是window对象,在Node.js指的是global对象。 ES5之中,全局对象的属性与全局变量是等价的,未声明的全局变量,自动成为全局对象window的属性。 从ES6开始,全局变量将逐步与全局对象的属性脱钩,let命令、const命令、class命令声明的全局变量,不属于全局对象的属性:
var a = 1;
// 如果在Node的REPL环境,可以写成global.a
// 或者采用通用方法,写成this.a
window.a // 1
let b = 1;
window.b // undefined
解构赋值
解构赋值的规则是,只要等号右边的值不是对象,就先将其转为对象。由于undefined和null无法转为对象,所以对它们进行解构赋值,都会报错。
- 数组的解构赋值;
var [a, b, c] = [1, 2, 3]; - 对象的解构赋值;
var { bar, foo } = { foo: "aaa", bar: "bbb" }; // 对象的属性没有次序,变量必须与属性同名,才能取到正确的值 - 字符串的解构赋值;
const [a, b, c, d, e] = 'hello'; - 数值和布尔值的解构赋值;
let {toString: s} = 123;
s === Number.prototype.toString // true
let {toString: s} = true;
s === Boolean.prototype.toString // true
- 函数参数的解构赋值;
function add([x, y]){
return x + y;
}
add([1, 2]); // 3
[[1, 2], [3, 4]].map(([a, b]) => a + b);
// [ 3, 7 ]
模板字符串
模板字符串(template string)是增强版的字符串,用反引号(`)标识。它可以当作普通字符串使用,也可以用来定义多行字符串,或者在字符串中嵌入变量。
// 普通字符串
`In JavaScript '\n' is a line-feed.`
// 多行字符串
`In JavaScript this is
not legal.`
console.log(`string text line 1
string text line 2`);
// 字符串中嵌入变量
var name = "Bob", time = "today";
`Hello ${name}, how are you ${time}?`
箭头函数
var f = v => v;
var f = () => 5;
var sum = (num1, num2) => num1 + num2;
var sum = (num1, num2) => { return num1 + num2; }
由于大括号被解释为代码块,所以如果箭头函数直接返回一个对象,必须在对象外面加上括号:
var getTempItem = id => ({ id: id, name: "Temp" });
箭头函数有几个使用注意点:
- 函数体内的this对象,就是定义时所在的对象,而不是使用时所在的对象。
function foo() {
setTimeout(() => {
console.log('id:', this.id);
}, 100);
}
var id = 21;
foo.call({ id: 42 });
// id: 42
- 不可以当作构造函数,也就是说,不可以使用new命令,否则会抛出一个错误。
- 不可以使用arguments对象,该对象在函数体内不存在。如果要用,可以用Rest参数代替。
- 不可以使用yield命令,因此箭头函数不能用作Generator函数。
箭头函数没有自己的this
箭头函数中this指向的固定化,并不是因为箭头函数内部有绑定this的机制,实际原因是箭头函数根本没有自己的this,导致内部的this就是外层代码块的this。正是因为它没有this,所以也就不能用作构造函数。箭头函数转成ES5的代码如下:
// ES6
function foo() {
setTimeout(() => {
console.log('id:', this.id);
}, 100);
}
// ES5
function foo() {
var _this = this;
setTimeout(function () {
console.log('id:', _this.id);
}, 100);
}
除了this,以下三个变量在箭头函数之中也是不存在的,指向外层函数的对应变量:arguments、super、new.target。
function foo() {
setTimeout(() => {
console.log('args:', arguments);
}, 100);
}
foo(2, 4, 6, 8)
// args: [2, 4, 6, 8]
由于箭头函数没有自己的this,所以当然也就不能用call()、apply()、bind()这些方法去改变this的指向。
尾调用优化与尾递归
尾调用(Tail Call)指某个函数的最后一步操作是返回另一个函数的调用。
function f(x){
return g(x);
}
不属于尾调用的情况:
// 情况一
function f(x){
let y = g(x); // 调用后还有操作
return y;
}
// 情况二
function f(x){
return g(x) + 1; // 调用后还有操作
}
// 情况三
function f(x){
g(x); // 相当于return undefined
}
尾调用优化:函数调用会在内存形成一个“调用记录”,又称“调用帧”(call frame),保存调用位置和内部变量等信息。如果在函数A的内部调用函数B,那么在A的调用帧上方,还会形成一个B的调用帧。等到B运行结束,将结果返回到A,B的调用帧才会消失。所有的调用帧,就形成一个“调用栈”(call stack)。尾调用由于是函数的最后一步操作,所以不需要保留外层函数的调用帧,因为调用位置、内部变量等信息都不会再用到了,只要直接用内层函数的调用帧,取代外层函数的调用帧就可以了。
function f() {
let m = 1;
let n = 2;
return g(m + n);
}
f();
// 等同于
function f() {
return g(3);
}
f();
// 等同于
g(3); // 由于调用g之后,函数f就结束了,所以执行到最后一步,完全可以删除 f(x) 的调用帧,只保留 g(3) 的调用帧。
“尾调用优化”(Tail call optimization),即只保留内层函数的调用帧。如果所有函数都是尾调用,那么完全可以做到每次执行时,调用帧只有一项,这将大大节省内存。这就是“尾调用优化”的意义。
尾递归:如果尾调用自身,就称为尾递归。递归非常耗费内存,因为需要同时保存成千上百个调用帧,很容易发生“栈溢出”错误(stack overflow)。但对于尾递归来说,由于只存在一个调用帧,所以永远不会发生“栈溢出”错误。 尾递归的实现,往往需要改写递归函数,确保最后一步只调用自身,做到这一点的方法,就是把所有用到的内部变量改写成函数的参数。:
// 阶乘函数,计算n的阶乘,最多需要保存n个调用记录,复杂度 O(n)
function factorial(n) {
if (n === 1) return 1;
return n * factorial(n - 1); // 不属于尾调用
}
factorial(5) // 120
阶乘函数 factorial 需要用到一个中间变量 total ,那就把这个中间变量改写成函数的参数,改写成尾递归:
// 复杂度 O(1)
function factorial(n, total) {
if (n === 1) return total;
return factorial(n - 1, n * total);
}
factorial(5, 1) // 120
“尾调用优化”对递归操作意义重大,所以一些函数式编程语言将其写入了语言规格。ES6也是如此,第一次明确规定,所有ECMAScript的实现,都必须部署“尾调用优化”。这就是说,在ES6中,只要使用尾递归,就不会发生栈溢出,相对节省内存。
ES6的尾调用优化只在严格模式下开启,正常模式是无效的。这是因为在正常模式下,函数内部有两个变量,可以跟踪函数的调用栈:func.arguments、func.caller尾调用优化发生时,函数的调用栈会改写,因此上面两个变量就会失真。严格模式禁用这两个变量,所以尾调用模式仅在严格模式下生效。
属性的遍历
ES6一共有5种方法可以遍历对象的属性。
-
for...infor…in循环遍历对象自身的和继承的可枚举属性(不含Symbol属性)。
-
Object.keys(obj)Object.keys返回一个数组,包括对象自身的(不含继承的)所有可枚举属性(不含Symbol属性)。
-
Object.getOwnPropertyNames(obj)Object.getOwnPropertyNames返回一个数组,包含对象自身的所有属性(不含Symbol属性,但是包括不可枚举属性)。
-
Object.getOwnPropertySymbols(obj)Object.getOwnPropertySymbols返回一个数组,包含对象自身的所有Symbol属性。
-
Reflect.ownKeys(obj)Reflect.ownKeys返回一个数组,包含对象自身的所有属性,不管是属性名是Symbol或字符串,也不管是否可枚举。
以上的5种方法遍历对象的属性,都遵守同样的属性遍历的次序规则:
首先遍历所有属性名为数值的属性,按照数字排序。
其次遍历所有属性名为字符串的属性,按照生成时间排序。
最后遍历所有属性名为Symbol值的属性,按照生成时间排序。
Reflect.ownKeys({ [Symbol()]:0, b:0, 10:0, 2:0, a:0 })
// ['2', '10', 'b', 'a', Symbol()]
Symbol
ES6引入了一种新的原始数据类型Symbol,表示独一无二的值。它是JavaScript语言的第七种数据类型,前六种是:Undefined、Null、布尔值(Boolean)、字符串(String)、数值(Number)、对象(Object)。 Symbol值通过Symbol函数生成。这就是说,对象的属性名现在可以有两种类型,一种是原来就有的字符串,另一种就是新增的Symbol类型。凡是属性名属于Symbol类型,就都是独一无二的,可以保证不会与其他属性名产生冲突。
Symbol函数前不能使用new命令,否则会报错。这是因为生成的Symbol是一个原始类型的值,不是对象。也就是说,由于Symbol值不是对象,所以不能添加属性。基本上,它是一种类似于字符串的数据类型。 Symbol函数可以接受一个字符串作为参数,表示对Symbol实例的描述,主要是为了在控制台显示,或者转为字符串时,比较容易区分。
let s = Symbol();
typeof s
// "symbol"
var s1 = Symbol('foo');
var s2 = Symbol('bar');
s1 // Symbol(foo)
s2 // Symbol(bar)
s1.toString() // "Symbol(foo)"
s2.toString() // "Symbol(bar)"
// 没有参数的情况
var s1 = Symbol();
var s2 = Symbol();
s1 === s2 // false
// 有参数的情况
var s1 = Symbol("foo");
var s2 = Symbol("foo");
s1 === s2 // false
二进制数组
二进制数组允许开发者以数组下标的形式,直接操作内存,使得开发者有可能通过JavaScript与操作系统的原生接口进行二进制通信。 二进制数组由三类对象组成
-
1.ArrayBuffer`对象:代表内存之中的一段二进制数据,可以通过“视图”进行操作。“视图”部署了数组接口,这意味着,可以用数组的方法操作内存。
-
2.TypedArray视图:是一组不同类型视图的统称,共包括9种类型的视图,比如Uint8Array(无符号8位整数)数组视图, Int16Array(16位整数)数组视图, Float32Array(32位浮点数)数组视图等等。
-
3.DataView视图:可以自定义复合格式的视图,比如第一个字节是Uint8(无符号8位整数)、第二、三个字节是Int16(16位整数)、第四个字节开始是Float32(32位浮点数)等等,此外还可以自定义字节序。
即,ArrayBuffer对象代表原始的二进制数据,TypedArray视图用来读写简单类型的二进制数据,DataView视图用来读写复杂类型的二进制数据。
注意,二进制数组并不是真正的数组,而是类似数组的对象。
WeakSet与Set的区别
-
- WeakSet的成员只能是对象,而不能是其他类型的值。
-
- WeakSet中的对象都是弱引用,即垃圾回收机制不考虑WeakSet对该对象的引用,也就是说,如果其他对象都不再引用该对象,那么垃圾回收机制会自动回收该对象所占用的内存,不考虑该对象还存在于WeakSet之中。这个特点意味着,无法引用WeakSet的成员(WeakSet没有size属性),因此WeakSet是不可遍历的。 WeakSet的一个用处,是储存DOM节点,而不用担心这些节点从文档移除时,会引发内存泄漏。
WeakMap与Map的区别
WeakMap结构与Map结构基本类似,唯一的区别是它只接受对象作为键名(null除外),不接受其他类型的值作为键名,而且键名所指向的对象,不计入垃圾回收机制。 WeakMap的设计目的在于,键名是对象的弱引用(垃圾回收机制不将该引用考虑在内),所以其所对应的对象可能会被自动回收。当对象被回收后,WeakMap自动移除对应的键值对。典型应用是,一个对应DOM元素的WeakMap结构,当某个DOM元素被清除,其所对应的WeakMap记录就会自动被移除。基本上,WeakMap的专用场合就是,它的键所对应的对象,可能会在将来消失。WeakMap结构有助于防止内存泄漏。 WeakMap与Map在API上的区别主要是两个,一是没有遍历操作(即没有key()、values()和entries()方法),也没有size属性;二是无法清空,即不支持clear方法。这与WeakMap的键不被计入引用、被垃圾回收机制忽略有关。因此,WeakMap只有四个方法可用:get()、set()、has()、delete()。
Iterator的遍历过程
-
- 创建一个指针对象,指向当前数据结构的起始位置。也就是说,遍历器对象本质上,就是一个指针对象。
-
- 第一次调用指针对象的next方法,可以将指针指向数据结构的第一个成员。
-
- 第二次调用指针对象的next方法,指针就指向数据结构的第二个成员。
-
- 不断调用指针对象的next方法,直到它指向数据结构的结束位置。 每一次调用next方法,都会返回数据结构的当前成员的信息。具体来说,就是返回一个包含value和done两个属性的对象。其中,value属性是当前成员的值,done属性是一个布尔值,表示遍历是否结束。
Iterator的作用有三个:
- 为各种数据结构,提供一个统一的、简便的访问接口;
- 使得数据结构的成员能够按某种次序排列;
- ES6创造了一种新的遍历命令for…of循环,Iterator接口主要供for…of消费。
由于Iterator只是把接口规格加到数据结构之上,所以,遍历器与它所遍历的那个数据结构,实际上是分开的,完全可以写出没有对应数据结构的遍历器对象,或者说用遍历器对象模拟出数据结构:
// 无限运行的遍历器对象
var it = idMaker();
it.next().value // '0'
it.next().value // '1'
it.next().value // '2'
// ...
function idMaker() {
var index = 0;
return {
next: function() {
return {value: index++, done: false};
}
};
}
Generator函数与yield语句
调用Generator函数后,该函数并不执行,返回的也不是函数运行结果,而是一个指向内部状态的指针对象,也就是遍历器对象(Iterator Object)。必须调用遍历器对象的next方法,使得指针移向下一个状态,每次调用next方法,内部指针就从函数头部或上一次停下来的地方开始执行,直到遇到下一个yield语句(或return语句)为止。换言之,Generator函数是分段执行的,yield语句是暂停执行的标记,而next方法可以恢复执行。
function* helloWorldGenerator() {
yield 'hello';
yield 'world';
return 'ending';
}
var hw = helloWorldGenerator();
hw.next()
// { value: 'hello', done: false }
hw.next()
// { value: 'world', done: false }
hw.next()
// { value: 'ending', done: true }
hw.next()
// { value: undefined, done: true }
遍历器对象的next方法的运行逻辑如下:
-
- 遇到yield语句,就暂停执行后面的操作,并将紧跟在yield后面的那个表达式的值,作为返回的对象的value属性值。
-
- 下一次调用next方法时,再继续往下执行,直到遇到下一个yield语句。
-
- 如果没有再遇到新的yield语句,就一直运行到函数结束,直到return语句为止,并将return语句后面的表达式的值,作为返回的对象的value属性值。
-
- 如果该函数没有return语句,则返回的对象的value属性值为undefined。
yield语句与return语句既有相似之处,也有区别。相似之处在于,都能返回紧跟在语句后面的那个表达式的值。区别在于每次遇到yield,函数暂停执行,下一次再从该位置继续向后执行,而return语句不具备位置记忆的功能。一个函数里面,只能执行一次(或者说一个)return语句,但是可以执行多次(或者说多个)yield语句。正常函数只能返回一个值,因为只能执行一次return;Generator函数可以返回一系列的值,因为可以有任意多个yield。从另一个角度看,也可以说Generator生成了一系列的值。
Generator与协程
一个线程(或函数)执行到一半,可以暂停执行,将执行权交给另一个线程(或函数),等到稍后收回执行权的时候,再恢复执行。这种可以并行执行、交换执行权的线程(或函数),就称为协程。它与普通的线程很相似,都有自己的执行上下文、可以分享全局变量。它们的不同之处在于,同一时间可以有多个线程处于运行状态,但是运行的协程只能有一个,其他协程都处于暂停状态。此外,普通的线程是抢先式的,到底哪个线程优先得到资源,必须由运行环境决定,但是协程是合作式的,执行权由协程自己分配。 从实现上看,在内存中,子例程只使用一个栈(stack),而协程是同时存在多个栈,但只有一个栈是在运行状态,也就是说,协程是以多占用内存为代价,实现多任务的并行。
Generator函数是ECMAScript 6对协程的实现,但属于不完全实现。Generator函数被称为“半协程”(semi-coroutine),意思是只有Generator函数的调用者,才能将程序的执行权还给Generator函数。如果是完全执行的协程,任何函数都可以让暂停的协程继续执行。 如果将Generator函数当作协程,完全可以将多个需要互相协作的任务写成Generator函数,它们之间使用yield语句交换控制权。
Promise对象
ES6原生提供了Promise对象。 Promise对象有以下两个特点。
-
- 对象的状态不受外界影响。Promise对象代表一个异步操作,有三种状态:Pending(进行中)、Resolved(已完成,又称Fulfilled)和Rejected(已失败)。只有异步操作的结果,可以决定当前是哪一种状态,任何其他操作都无法改变这个状态。这也是Promise这个名字的由来,它的英语意思就是“承诺”,表示其他手段无法改变。
-
- 一旦状态改变,就不会再变,任何时候都可以得到这个结果。Promise对象的状态改变,只有两种可能:从Pending变为Resolved和从Pending变为Rejected。只要这两种情况发生,状态就凝固了,不会再变了,会一直保持这个结果。就算改变已经发生了,你再对Promise对象添加回调函数,也会立即得到这个结果。这与事件(Event)完全不同,事件的特点是,如果你错过了它,再去监听,是得不到结果的。 有了Promise对象,就可以将异步操作以同步操作的流程表达出来,避免了层层嵌套的回调函数。此外,Promise对象提供统一的接口,使得控制异步操作更加容易。 Promise也有一些缺点。首先,无法取消Promise,一旦新建它就会立即执行,无法中途取消。其次,如果不设置回调函数,Promise内部抛出的错误,不会反应到外部。第三,当处于Pending状态时,无法得知目前进展到哪一个阶段(刚刚开始还是即将完成)。
传值调用与传名调用
var x = 1;
function f(m){
return m * 2;
}
f(x + 5)
传值调用:即在进入函数体之前,就计算x + 5的值(等于6),再将这个值传入函数f 。C语言就采用这种策略。
f(x + 5)
// 传值调用时,等同于
f(6)
传名调用:即直接将表达式x + 5传入函数体,只在用到它的时候求值。Haskell语言采用这种策略。
f(x + 5)
// 传名调用时,等同于
(x + 5) * 2
编译器的”传名调用”实现,往往是将参数放到一个临时函数之中,再将这个临时函数传入函数体。这个临时函数就叫做Thunk函数:
function f(m){
return m * 2;
}
f(x + 5);
// 等同于
var thunk = function () {
return x + 5;
};
function f(thunk){
return thunk() * 2;
}
凡是用到原参数的地方,对Thunk函数求值即可。这就是Thunk函数的定义,它是”传名调用”的一种实现策略,用来替换某个表达式。
async函数语法
- 1.async函数返回一个Promise对象 async函数内部return语句返回的值,会成为then方法回调函数的参数:
async function f() {
return 'hello world';
}
f().then(v => console.log(v))
// "hello world"
async函数内部抛出错误,会导致返回的Promise对象变为reject状态。抛出的错误对象会被catch方法回调函数接收到。
-
2.async函数返回的Promise对象,必须等到内部所有await命令的Promise对象执行完,才会发生状态改变。也就是说,只有async函数内部的异步操作执行完,才会执行then方法指定的回调函数。
-
3.正常情况下,await命令后面是一个Promise对象。如果不是,会被转成一个立即resolve的Promise对象。
-
4.如果await后面的异步操作出错,那么等同于async函数返回的Promise对象被reject。
async函数对Generator函数的改进
- 1.内置执行器。Generator函数的执行必须靠执行器,所以才有了co模块,而async函数自带执行器。也就是说,async函数的执行,与普通函数一模一样,只要一行。 var result = asyncReadFile(); 上面的代码调用了asyncReadFile函数,然后它就会自动执行,输出最后结果。这完全不像Generator函数,需要调用next方法,或者用co模块,才能得到真正执行,得到最后结果。
- 2.更好的语义。async和await,比起星号和yield,语义更清楚了。async表示函数里有异步操作,await表示紧跟在后面的表达式需要等待结果。
- 3.更广的适用性。 co模块约定,yield命令后面只能是Thunk函数或Promise对象,而async函数的await命令后面,可以是Promise对象和原始类型的值(数值、字符串和布尔值,但这时等同于同步操作)。
- 4.返回值是Promise。async函数的返回值是Promise对象,这比Generator函数的返回值是Iterator对象方便多了。可以用then方法指定下一步的操作。 进一步说,async函数完全可以看作多个异步操作,包装成的一个Promise对象,而await命令就是内部then命令的语法糖。
Class
基本上,ES6的class可以看作只是一个语法糖,它的绝大部分功能,ES5都可以做到,新的class写法只是让对象原型的写法更加清晰、更像面向对象编程的语法而已。ES6的类,完全可以看作构造函数的另一种写法:
class Point {
// ...
}
typeof Point // "function"
Point === Point.prototype.constructor // true
使用的时候,也是直接对类使用new命令,跟构造函数的用法完全一致。
类的prototype属性和__proto__属性
Class作为构造函数的语法糖,同时有prototype属性和__proto__属性,因此同时存在两条继承链。
-
- 子类的__proto__属性,表示
构造函数的继承,总是指向父类。
- 子类的__proto__属性,表示
-
- 子类prototype属性的__proto__属性,表示
方法的继承,总是指向父类的prototype属性。
- 子类prototype属性的__proto__属性,表示
class A {
}
class B extends A {
}
B.__proto__ === A // true
B.prototype.__proto__ === A.prototype // true
这样的结果是因为,类的继承是按照下面的模式实现的:
class A {
}
class B {
}
// B的实例继承A的实例
Object.setPrototypeOf(B.prototype, A.prototype);
// B继承A的静态属性
Object.setPrototypeOf(B, A);
这两条继承链,可以这样理解:作为一个对象,子类(B)的原型(__proto__属性)是父类(A);作为一个构造函数,子类(B)的原型(prototype属性)是父类的实例。
Module
在ES6之前,社区制定了一些模块加载方案,最主要的有CommonJS和AMD两种。前者用于服务器,后者用于浏览器。ES6在语言规格的层面上,实现了模块功能,而且实现得相当简单,完全可以取代现有的CommonJS和AMD规范,成为浏览器和服务器通用的模块解决方案。
ES6模块的设计思想,是尽量的静态化,使得编译时就能确定模块的依赖关系,以及输入和输出的变量。CommonJS和AMD模块,都只能在运行时确定这些东西。比如,CommonJS模块就是对象,输入时必须查找对象属性。
// CommonJS模块
let { stat, exists, readFile } = require('fs');
// 等同于
let _fs = require('fs');
let stat = _fs.stat, exists = _fs.exists, readfile = _fs.readfile;
上面代码的实质是整体加载fs模块(即加载fs的所有方法),生成一个对象(_fs),然后再从这个对象上面读取3个方法。这种加载称为“运行时加载”,因为只有运行时才能得到这个对象,导致完全没办法在编译时做“静态优化”。
ES6模块不是对象,而是通过export命令显式指定输出的代码,输入时也采用静态命令的形式。
// ES6模块
import { stat, exists, readFile } from 'fs';
上面代码的实质是从fs模块加载3个方法,其他方法不加载。这种加载称为“编译时加载”,即ES6可以在编译时就完成模块加载,效率要比CommonJS模块的加载方式高。由于ES6模块是编译时加载,使得静态分析成为可能。
浏览器使用ES6模块的语法如下:
<script type="module" src="foo.js"></script>
严格模式的限制
- 变量必须声明后再使用;
- 函数的参数不能有同名属性,否则报错;
- 不能使用with语句;
- 不能对只读属性赋值,否则报错;
- 不能使用前缀0表示八进制数,否则报错;
- 不能删除不可删除的属性,否则报错;
- 不能删除变量delete prop,会报错,只能删除属性delete global[prop];
- eval不会在它的外层作用域引入变量;
- eval和arguments不能被重新赋值;
- arguments不会自动反映函数参数的变化;
- 不能使用arguments.callee;
- 不能使用arguments.caller;
- 禁止this指向全局对象;
- 不能使用fn.caller和fn.arguments获取函数调用的堆栈;
- 增加了保留字(比如protected、static和interface);
ES6模块加载与CommonJS模块加载的区别
CommonJS模块输出的是一个值的拷贝,而ES6模块输出的是值的引用。 ES6模块的运行机制与CommonJS不一样,它遇到模块加载命令import时,不会去执行模块,而是只生成一个动态的只读引用。等到真的需要用到时,再到模块里面去取值,换句话说,ES6的输入有点像Unix系统的“符号连接”,原始值变了,import输入的值也会跟着变。因此,ES6模块是动态引用,并且不会缓存值,模块里面的变量绑定其所在的模块。
CommonJS模块的重要特性是加载时执行,即脚本代码在require的时候,就会全部执行。一旦出现某个模块被”循环加载”,就只输出已经执行的部分,还未执行的部分不会输出。
ES6处理“循环加载”与CommonJS有本质的不同。ES6模块是动态引用,如果使用import从一个模块加载变量(即import foo from ‘foo’),那些变量不会被缓存,而是成为一个指向被加载模块的引用,需要开发者自己保证,真正取值的时候能够取到值。(即,可能会由于循环加载导致取到的值为undefined)
不同DOM级别的内容
实际上,DOM0 级标准是不存在的;所谓 DOM0 级只是 DOM 历史坐标中的一个参照点而已。具体说来,DOM0 级指的是 Internet Explorer 4.0 和 Netscape Navigator 4.0最初支持的 DHTML。 DOM1级由两个模块组成:DOM核心(DOM Core)和 DOM HTML。其中,DOM 核心规定的是如何映射基于 XML 的文档结构,以便简化对文档中任意部分的访问和操作。DOM HTML 模块则在 DOM 核心的基础上加以扩展,添加了针对HTML的对象和方法。 DOM2级在原来 DOM 的基础上又扩充了(DHTML 一直都支持的)鼠标和用户界面事件、范围、遍历(迭代 DOM 文档的方法)等细分模块,而且通过对象接口增加了对 CSS(Cascading Style Sheets,层叠样式表)的支持。DOM1 级中的 DOM 核心模块也经过扩展开始支持 XML 命名空间。 DOM3级则进一步扩展了 DOM,引入了以统一方式加载和保存文档的方法——在 DOM 加载和保存(DOM Load and Save)模块中定义;新增了验证文档的方法——在 DOM 验证(DOM Validation)模块中定义。DOM3 级也对 DOM 核心进行了扩展,开始支持 XML 1.0 规范,涉及 XML Infoset、XPath和 XML Base。
undefined值是派生自null值的
实际上,undefined值是派生自null值的,因此ECMA-262规定对它们的相等性测试要返回true:
alert(null == undefined); //true
要注意的是,这个操作符出于比较的目的会转换其操作数。 尽管null和undefined有这样的关系,但它们的用途完全不同。如前所述,无论在什么情况下都没有必要把一个变量的值显式地设置为undefined ,可是同样的规则对null却不适用。换句话说,只要意在保存对象的变量还没有真正保存对象,就应该明确地让该变量保存null值。这样做不仅可以体现null作为空对象指针的惯例,而且也有助于进一步区分null和undefined 。
直接使用浮点数相等性比较的问题
浮点数值的最高精度是 17 位小数,但在进行算术计算时其精确度远远不如整数。例如,0.1 加 0.2 的结果不是 0.3,而是 0.30000000000000004。这个小小的舍入误差会导致无法测试特定的浮点数值。 例如:
if (a + b == 0.3){ // 不要做这样的测试!
alert("You got 0.3.");
}
NaN、Infinity
Number类型的取值范围是Number.MIN_VALUE~Number.MAX_VALUE
如果某次计算的结果得到了一个超出 JavaScript 数值范围的值,那么这个数值将被自动转换成特殊的 Infinity 值
要想确定一个数值是不是有穷的(换句话说,是不是位于最小和最大的数值之间),可以使用 isFinite() 函数。
NaN ,即非数值(Not a Number),是一个特殊的数值,用于表示一个本来要返回数值的操作数 未返回数值的情况。例如,在 ECMAScript中,任何数值除以 0会返回 NaN
NaN 与任何值都不相等,包括 NaN 本身。
ECMAScript 定义了isNaN()函数用于判断一个数值是否为NaN:
alert(isNaN(NaN)); //true
alert(isNaN("blue")); //true(不能转换成数值)
alert(isNaN("10")); //false(可以被转换成数值 10)
isNaN() 也适用于对象。在基于对象调用 isNaN()函数时,会首先调用对象的 valueOf() 方法,然后确定该方法返回的值是否可以转换为数值。如果不能,则基于这个返回值再调用 toString() 方法,再测试返回值。
是否所有类型的对象都可以通过调用toString()来将其转换为字符串?
数值、布尔值、对象和字符串值都有 toString() 方法。但 null 和 undefined 值没有这个方法。在不知道要转换的值是不是 null 或 undefined 的情况下,还可以使用转型函数 String() ,这个函数能够将任何类型的值转换为字符串。 String() 函数遵循下列转换规则: 如果值有 toString() 方法,则调用该方法(没有参数)并返回相应的结果; 如果值是 null ,则返回 “null” ; 如果值是 undefined ,则返回 “undefined” 。
Object实例具有的属性和方法
Object 的每个实例都具有下列属性和方法。 constructor :保存着用于创建当前对象的构造函数 hasOwnProperty(propertyName) :用于检查给定的属性在当前对象实例中(而不是在实例的原型中)是否存在。其中,作为参数的属性名( propertyName )必须以字符串形式指定(例如: o.hasOwnProperty(“name”) )。 isPrototypeOf(object) :用于检查传入的对象是否是传入对象的原型。 propertyIsEnumerable(propertyName) :用于检查给定的属性是否能够使用 for-in 语句来枚举 toLocaleString() :返回对象的字符串表示,该字符串与执行环境的地区对应。 toString() :返回对象的字符串表示。 valueOf() :返回对象的字符串、数值或布尔值表示。通常与 toString() 方法的返回值相同。
使用for-in语句来枚举对象的属性
for (var propName in window) {
document.write(propName);
}
ECMAScript 对象的属性没有顺序。因此,通过 for-in 循环输出的属性名的顺序是不可预测的。 如果表示要迭代的对象的变量值为 null 或 undefined , for-in 语句会抛出错误。 ECMAScript 5 更正了这一行为;对这种情况不再抛出错误,而只是不执行循环体。为了保证最大限度的 兼容性,建议在使用 for-in 循环之前,先检测确认该对象的值不是 null 或 undefined
label语句
使用 label 语句可以在代码中添加标签,以便将来使用。以下是 label 语句的语法: label: statement 下面是一个示例:
start: for (var i=0; i < count; i++) {
alert(i);
}
这个例子中定义的 start 标签可以在将来由 break 或 continue 语句引用。加标签的语句一般都 要与 for 语句等循环语句配合使用。
with语句
with 语句的作用是将代码的作用域设置到一个特定的对象中。 with 语句的语法如下: with (expression) statement; 定义 with 语句的目的主要是为了简化多次编写同一个对象的工作,如下面的例子所示:
var qs = location.search.substring(1);
var hostName = location.hostname;
var url = location.href;
上面几行代码都包含 location 对象。如果使用 with 语句,可以把上面的代码改写成如下所示:
with(location){
var qs = search.substring(1);
var hostName = hostname;
var url = href;
}
这意味着在 with 语句的代码块内部,每个变量首先被认为是一个局部变量,而如果在局部环境中找不到该变量的定义,就会查询location 对象中是否有同名的属性。如果发现了同名属性,则以 location 对象属性的值作为变量的值。
arguments对象
ECMAScript 函数的参数与大多数其他语言中函数的参数有所不同。ECMAScript 函数不介意传递进来多少个参数,也不在乎传进来参数是什么数据类型。也就是说,即便你定义的函数只接收两个参数,在调用这个函数时也未必一定要传递两个参数。可以传递一个、三个甚至不传递参数,而解析器永远不会有什么怨言。之所以会这样,原因是 ECMAScript 中的参数在内部是用一个数组来表示的。函数接收到的始终都是这个数组,而不关心数组中包含哪些参数(如果有参数的话)。如果这个数组中不包含任何元素,无所谓;如果包含多个元素,也没有问题。实际上,在函数体内可以通过 arguments 对象来访问这个参数数组,从而获取传递给函数的每一个参数。
function sayHi() {
alert("Hello " + arguments[0] + "," + arguments[1]);
}
这个事实说明了 ECMAScript 函数的一个重要特点:命名的参数只提供便利,但不是必需的。 arguments 对象可以与命名参数一起使用,且它的值永远与对应命名参数的值保持同步。不过,这并不是说读取这两个值会访问相同的内存空间;它们的内存空间是独立的,但它们的值会同步。 如果只传入了一个参数,那么为 arguments[1] 设置的值不会反应到命名参数中。这是因为 arguments 对象的长度是由传入的参数个数决定的,不是由定义函数时的命名参数的个数决定的。
ECMAScript 中的所有参数传递的都是值,不可能通过引用传递参数。
ECMAScript中支持函数重载吗?如果定义了同名的函数会怎样?
ECMAScript 函数不能像传统意义上那样实现重载,如果在 ECMAScript中定义了两个名字相同的函数,则该名字只属于后定义的函数:
function addSomeNumber(num){
return num + 100;
}
function addSomeNumber(num) {
return num + 200;
}
var result = addSomeNumber(100); //300
执行环境
执行环境定义了变量或函数有权访问的其他数据,决定了它们各自的行为。每个执行环境都有一个与之关联的变量对象(variable object),环境中定义的所有变量和函数都保存在这个对象中。虽然我们编写的代码无法访问这个对象,但解析器在处理数据时会在后台使用它。
全局执行环境是最外围的一个执行环境。根据 ECMAScript 实现所在的宿主环境不同,表示执行环境的对象也不一样。在 Web 浏览器中,全局执行环境被认为是 window 对象,因此所有全局变量和函数都是作为 window 对象的属性和方法创建的。某个执行环境中的所有代码执行完毕后,该环境被销毁,保存在其中的所有变量和函数定义也随之销毁(全局执行环境直到应用程序退出——例如关闭网页或浏览器——时才会被销毁)。
每个函数都有自己的执行环境。当执行流进入一个函数时,函数的环境就会被推入一个环境栈中。而在函数执行之后,栈将其环境弹出,把控制权返回给之前的执行环境。ECMAScript 程序中的执行流正是由这个方便的机制控制着。
作用域链
当代码在一个环境中执行时,会创建变量对象的一个作用域链(scope chain)。作用域链的用途,是保证对执行环境有权访问的所有变量和函数的有序访问。作用域链的前端,始终都是当前执行的代码所在环境的变量对象。如果这个环境是函数,则将其活动对象(activation object)作为变量对象。活动对象在最开始时只包含一个变量,即 arguments 对象(这个对象在全局环境中是不存在的)。作用域链中的下一个变量对象来自包含(外部)环境,而再下一个变量对象则来自下一个包含环境。这样,一直延续到全局执行环境;全局执行环境的变量对象始终都是作用域链中的最后一个对象。 标识符解析是沿着作用域链一级一级地搜索标识符的过程。搜索过程始终从作用域链的前端开始,然后逐级地向后回溯。
内部环境可以通过作用域链访问所有的外部环境,但外部环境不能访问内部环境中的任何变量和函数。这些环境之间的联系是线性、有次序的。每个环境都可以向上搜索作用域链,以查询变量和函数名;但任何环境都不能通过向下搜索作用域链而进入另一个执行环境。
延长作用域链
有些语句可以在作用域链的前端临时增加一个变量对象,该变量对象会在代码执行后被移除。在两种情况下会发生这种现象。具体来说,就是当执行流进入下列任何一个语句时,作用域链就会得到加长: try-catch 语句的 catch 块; with 语句。
JavaScript是否有块级作用域?
JavaScript 没有块级作用域
if (true) {
var color = "blue";
}
alert(color); //"blue"
使用 var 声明的变量会自动被添加到最接近的环境中。在函数内部,最接近的环境就是函数的局部环境;在 with 语句中,最接近的环境是函数环境。如果初始化变量时没有使用 var 声明,该变量会自动被添加到全局环境。
JavaScript的垃圾回收机制有哪些方式?如何优化JavaScript的内存占用?
JavaScript具有自动垃圾收集机制,执行环境会负责管理代码执行过程中使用的内存。这种垃圾收集机制的原理其实很简单:找出那些不再继续使用的变量,然后释放其占用的内存。为此,垃圾收集器会按照固定的时间间隔(或代码执行中预定的收集时间),周期性地执行这一操作。具体到浏览器中的实现,则通常有两个策略:标记清除、引用计数。
- 标记清除
当变量进入环境(例如,在函数中声明一个变量)时,就将这个变量标记为“进入环境”。从逻辑上讲,永远不能释放进入环境的变量所占用的内存,因为只要执行流进入相应的环境,就可能会用到它们。而当变量离开环境时,则将其标记为“离开环境”。
- 引用计数
跟踪记录每个值被引用的次数。当声明了一个变量并将一个引用类型值赋给该变量时,则这个值的引用次数就是 1。如果同一个值又被赋给另一个变量,则该值的引用次数加 1。相反,如果包含对这个值引用的变量又取得了另外一个值,则这个值的引用次数减 1。当这个值的引用次数变成 0 时,则说明没有办法再访问这个值了,因而就可以将其占用的内存空间回收回来。 Netscape Navigator 3.0是最早使用引用计数策略的浏览器,但很快它就遇到了一个严重的问题:循环引用。循环引用指的是对象 A 中包含一个指向对象 B 的指针,而对象 B 中也包含一个指向对象 A 的引用。为此,Netscape 在 Navigator 4.0 中放弃了引用计数方式,转而采用标记清除来实现其垃圾收集机制。
优化内存占用的最佳方式,就是为执行中的代码只保存必要的数据。一旦数据不再有用,最好通过将其值设置为 null 来释放其引用——这个做法叫做解除引用(dereferencing)。这一做法适用于大多数全局变量和全局对象的属性。局部变量会在它们离开执行环境时自动被解除引用
function createPerson(name){
var localPerson = new Object();
localPerson.name = name;
return localPerson;
}
var globalPerson = createPerson("Nicholas");
// 手工解除 globalPerson 的引用
globalPerson = null;
解除一个值的引用并不意味着自动回收该值所占用的内存。解除引用的真正作用是让值脱离执行环境,以便垃圾收集器下次运行时将其回收。 基本类型值在内存中占据固定大小的空间,因此被保存在栈内存中;引用类型的值是对象,保存在堆内存中;
在JavaScript中通过对象字面量方式定义对象与通过构造函数方式定义对象有什么不同?
普通的创建引用实例的方式:
var person = new Object();
person.name = "Nicholas";
person.age = 29;
使用对象字面量方式创建:
var person = {
name : "Nicholas",
age : 29 // 在最后一个属性后面添加逗号会在IE7及更早版本,以及Opera中出错
};
在使用对象字面量语法时,属性名也可以使用字符串:
var person = {
"name" : "Nicholas",
"age" : 29,
5 : true // 数值属性名会自动转换为字符串
};
在通过对象字面量定义对象时,实际上不会调用 Object 构造函数。
在JavaScript中使用方括号表示法访问对象属性与使用点表示法访问对象属性有什么不同?
方括号语法的主要优点是可以通过变量 来访问属性,例如:
var propertyName = "name";
alert(person[propertyName]); //"Nicholas"
如果属性名中包含会导致语法错误的字符,或者属性名使用的是关键字或保留字,也可以使用方括 号表示法。例如:
person["first name"] = "Nicholas";
数组的length属性
数组的项数保存在其 length 属性中。如果设置某个值的索引超过了数组现有项数,数组就会自动增加到该索引值加 1 的长度:
var colors = ["red", "blue", "green"]; // 定义一个字符串数组
alert(colors[0]); // 显示第一项
colors[2] = "black"; // 修改第三项
colors[3] = "brown"; // 新增第四项
length 属性不是只读的。因此,通过设置这个属性,可以从数组的末尾移除项或向数组中添加新项:
var colors = ["red", "blue", "green"]; // 创建一个包含 3 个字符串的数组
colors.length = 2;
alert(colors[2]); //undefined
var colors = ["red", "blue", "green"]; // 创建一个包含 3 个字符串的数组
colors.length = 4;
alert(colors[3]); //undefined
使用instanceof操作符来判断一个变量是否是数组类型存在什么问题?如何解决?
对于一个网页,或者一个全局作用域而言,使用 instanceof 操作符就能得到满意的结果:
if (value instanceof Array){
//对数组执行某些操作
}
instanceof 操作符的问题在于,它假定只有一个全局执行环境。如果网页中包含多个框架,那实际上就存在两个以上不同的全局执行环境,从而存在两个以上不同版本的 Array 构造函数。如果从一个框架向另一个框架传入一个数组,那么传入的数组与在第二个框架中原生创建的数组分别具有各自不同的构造函数。
为了解决这个问题,ECMAScript 5 新增了 Array.isArray() 方法。这个方法的目的是最终确定某个值到底是不是数组,而不管它是在哪个全局执行环境中创建的:
if (Array.isArray(value)){
//对数组执行某些操作
}
JavaScript原生的操作数组的方法
join()
push() // 接收任意数量的参数,把它们逐个添加到数组末尾,并返回修改后数组的长度
pop() // 从数组末尾移除最后一项,减少数组的 length 值,然后返回移除的项
shift() // 移除数组中的第一个项并返回该项,同时将数组长度减 1
unshift() // 在数组前端添加任意个项并返回新数组的长度
sort() // 默认调用每一项的toString()值进行升序排列(所以15排在5前面),可以指定一个比较函数
reverse()
concat()
slice() // 基于位置参数从当前数组中创建一个新数组(该方法不会影响原数组)
splice() // 可以用于删除、插入、替换数组元素
indexOf() // 会使用全等操作进行比较
lastIndexOf()
every() // 如果指定函数对每一项都返回 true ,则返回 true
filter() // 返回指定函数会返回 true 的项组成的数组
forEach() // 对数组中的每一项运行指定函数,没有返回值
map() // 返回每次指定函数调用的结果组成的数组
some() // 如果指定函数对任一项返回 true ,则返回 true
reduce() // 用指定函数迭代数组的所有项,然后构建一个最终返回的值。从数组的第一项开始,逐个遍历到最后。指定函数包含4个参数:前一个值、当前值、项的索引和数组对象。这个函数返回的任何值都会作为第一个参数自动传给下一项。第一次迭代发生在数组的第二项上,因此第一个参数是数组的第一项,第二个参数就是数组的第二项。
var values = [1,2,3,4,5];
var sum = values.reduce(function(prev, cur, index, array){
return prev + cur;
});
alert(sum); //15
reduceRight()
定义JavaScript函数的方式
函数实际上是对象。每个函数都是 Function 类型的实例,而且都与其他引用类型一样具有属性和方法。由于函 数是对象,因此函数名实际上也是一个指向函数对象的指针,不会与某个函数绑定:
function sum (num1, num2) {
return num1 + num2;
}
这与下面使用函数表达式定义函数的方式几乎相差无几(注意函数末尾有一个分号)
// 在使用函数表达式定义函数时,没有必要使用函数名
var sum = function(num1, num2){
return num1 + num2;
};
也可以使用 Function 构造函数来定义函数:
var sum = new Function("num1", "num2", "return num1 + num2"); // 不推荐
不推荐使用这种方法定义函数,因为这种语法会导致解析两次代码(第一次是解析常规 ECMAScript代码,第二次是解析传入构造函数中的字符串),从而影响性能。
解析器在向执行环境中加载数据时,对函数声明和函数表达式并非一视同仁。解析器会率先读取函数声明,并使其在执行任何代码之前可用(可以访问);至于函数表达式,则必须等到解析器执行到它所在的代码行,才会真 正被解释执行
alert(sum(10,10)); // OK
function sum(num1, num2){
return num1 + num2;
}
在代码开始执行之前,解析器就已经通过一个名为函数声明提升(function declaration hoisting)的过程,读取并将函数声明添加到执行环境中。
alert(sum(10,10)); // FAILED
var sum = function(num1, num2){
return num1 + num2;
};
JavaScript函数拥有的属性和方法
arguments //包含着传入函数中的所有参数。
// 这个对象还有一个名叫 callee 的属性,该属性是一个指针,指向拥有这个 arguments 对象的函数
this // 指向函数据以执行的`环境对象`
caller // 保存着调用当前函数的函数的引用
length // 表示函数希望接收的命名参数的个数
prototype // (所有引用类型)保存所有实例方法的真正所在, prototype 属性是不可枚举的,因此使用 for-in 无法发现
apply() // 在特定的作用域中调用函数,接收两个参数:一个是在其中运行函数的作用域,另一个是参数数组
call() // 传递给函数的参数必须逐个列举出
bind() // 创建一个函数的实例,其 this 值会被绑定到传给 bind() 函数的值
函数继承的 toLocaleString() 和 toString() ,valueOf()方法始终都返回函数的代码
基本包装类型
为了便于操作基本类型值,ECMAScript 还提供了 3 个特殊的引用类型: Boolean 、 Number 和
String 。实际上,每当读取一个基本类型值的时候,后台就会创建一个对应的基本包装类型的对象,从而让我们
能够调用一些方法来操作这些数据。来看下面的例子。
var s1 = "some text";
var s2 = s1.substring(2);
可以将以上三个步骤想象成是执行了下列 ECMAScript 代码。
var s1 = new String("some text");
var s2 = s1.substring(2);
s1 = null;
引用类型与基本包装类型的主要区别就是对象的生存期。使用 new 操作符创建的引用类型的实例,在执行流离开当前作用域之前都一直保存在内存中。而自动创建的基本包装类型的对象,则只存在于一行代码的执行瞬间,然后立即被销毁。这意味着我们不能在运行时为基本类型值添加属性和方法。
var s1 = "some text";
s1.color = "red";
alert(s1.color); //undefined
第二行创建的 String 对象在执行第三行代码时已经被销毁了。第三行代码又创建自己的 String 对象,而该对象没有 color 属性。
Object 构造函数也会像工厂方法一样,根据传入值的类型返回相应基本包装类型的实例。例如:
var obj = new Object("some text");
alert(obj instanceof String); //true
使用 new 调用基本包装类型的构造函数,与直接调用同名的转型函数是不一样的。 例如:
var value = "25";
var number = Number(value); //转型函数
alert(typeof number); //"number"
var obj = new Number(value); //构造函数
alert(typeof obj); //"object"
为什么说Boolean 对象在 ECMAScript 中的用处不大?
var falseObject = new Boolean(false);
var result = falseObject && true;
alert(result); //true
var falseValue = false;
result = falseValue && true;
alert(result); //false
alert(typeof falseObject); //object
alert(typeof falseValue); //boolean
alert(falseObject instanceof Boolean); //true
alert(falseValue instanceof Boolean); //false
布尔表达式中的所有对象都会被转换为 true ,因此 false Object 对象在布尔表达式中代表的是 true 。
建议是永远不要使用 Boolean 对象。
不建议直接实例化 Number 类型,而原因与显式创建 Boolean 对象一样:在使用typeof 和 instanceof 操作符测试基本类型数值与引用类型数值时,得到的结果完全不同。
String类型的实例的属性和方法
length // 表示字符串中包含多个字符, 即使字符串中包含双字节字符(不是占一个字节的 ASCII 字符),每个字符也仍然算一个字符
charAt() // 返回字符(也可以使用方括号加数字索引来访问字符串中的特定字符)
charCodeAt() // 返回字符的编码
concat() // 用于将一或多个字符串拼接起来(更多的是直接使用+操作符)
slice() // 第二个参数指定的是子字符串最后一个字符后面的位置
substr() // 第二个参数指定的是返回的字符个数
substring() // 第二个参数指定的是子字符串最后一个字符后面的位置
indexOf() // 可以接收可选的第二个参数,表示从字符串中的哪个位置开始搜索
lastIndexOf()
trim() //删除前置及后缀的所有空格,然后返回结果
toLowerCase()
toLocaleLowerCase()
toUpperCase()
toLocaleUpperCase()
match() // 在字符串上调用这个方法,本质上与调用 RegExp 的 exec() 方法相同,只接受一个参数,要么是一
个正则表达式,要么是一个 RegExp 对象
search() // 参数与match相同,返回字符串中第一个匹配项的索引
replace() //第一个参数可以是一个 RegExp 对象或者一个字符串(这个字符串不会被转换成正则表达式),第二个参
数可以是一个字符串或者一个函数。如果第一个参数是字符串,那么只会替换第一个子字符串。要想替
换所有子字符串,唯一的办法就是提供一个正则表达式,而且要指定全局( g )标志
split() //分隔符可以是字符串,也可以是一个 RegExp 对象,可以接受可选的第二个参数,用于指定数组的大小
String.fromCharCode // String 构造函数本身还有一个静态方法,与实例方法 charCodeAt()执行的是相反的操作
alert(String.fromCharCode(104, 101, 108, 108, 111)); //"hello"
Global对象的属性和方法
ECMAScript 中的 Global 对象在某种意义上是作为一个终极的“兜底儿对象”来定义的。换句话说,不属于任何其他对象的属性和方法,最终都是它的属性和方法。事实上,没有全局变量或全局函数;所有在全局作用域中定义的属性和函数,都是 Global 对象的属性。在所有代码执行之前,作用域中就已经存在两个内置对象: Global 和 Math
encodeURI() // 对 URI进行编码,以便发送给浏览器,不会对本身属于 URI 的特殊字符进行编码,例如冒号、正斜杠、问号和井字号
encodeURIComponent() // 会对它发现的任何非标准字符进行编码
decodeURI()
decodeURIComponent()
escape() 和 unescape()已经被废弃,因为它们只能处理ASCII
eval() // 就像是一个完整的 ECMAScript 解析器,它只接受一个参数,即要执行的 ECMAScript字符串。当解析器发现代码中调用 eval() 方法时,它会将传入的参数当作实际的 ECMAScript 语句来解析,然后把执行结果插入到原位置。通过 eval() 执行的代码被认为是包含该次调用的执行环境的一部分,因此被执行的代码具有与该执行环境相同的作用域链。这意味着通过 eval() 执行的代码可以引用在包含环境中定义的变量:
var msg = "hello world";
eval("alert(msg)"); //"hello world"
eval("function sayHi() { alert('hi'); }");
sayHi();
在 eval() 中创建的任何变量或函数都不会被提升,因为在解析代码的时候,它们被包含在一个字符串中;它们只在 eval() 执行的时候创建。
undefined NaN Infinity 所有原生引用类型的构造函数,像Object 、Function、各种Error ,也都是 Global 对象的属性
Global对象与Windows对象有什么区别?
在大多数 ECMAScript实现中都不能直接访问 Global 对象;不过,Web 浏览器实现了承担该角色的 window 对象。全局变量和函数都是 Global 对象的属性。Web 浏览器都是将Global全局对象作为window 对象的一部分加以实现的。因此,在全局作用域中声明的所有变量和函数,就都成为了 window对象的属性:
var color = "red";
function sayColor(){
alert(window.color);
}
window.sayColor(); //"red"
JavaScript中的 window 对象除了扮演ECMAScript规定的 Global 对象的角色外,还承担了很多别的任务。
另一种取得 Global 对象的方法是使用以下代码:
// 立即调用的函数表达式
var global = function(){
return this;
}();
什么是attribute?与property有什么关系?有哪些attribute?有哪些property?
特性(attribute)用来描述属性(property)的各种特征,特性是为了实现 JavaScript 引擎用的,因此在 JavaScript 中不能直接访问它们。为了表示特性是内部值,ECMA-262规范把它们放在了两对方括号中,例如 [[Enumerable]]
ECMAScript 中有两种属性:数据属性和访问器属性。 数据属性包含一个数据值的位置。在这个位置可以读取和写入值。数据属性有 4 个描述其行为的 特性。
[[Configurable]]
[[Enumerable]]
[[Writable]]
[[Value]]
要修改属性默认的特性,必须使用 ECMAScript 5 的 Object.defineProperty() 方法:
var person = {};
Object.defineProperty(person, "name", {
writable: false,
value: "Nicholas"
});
alert(person.name); //"Nicholas"
person.name = "Greg";
alert(person.name); //"Nicholas"
访问器属性不包含数据值;它们包含一对getter和setter函数(不过,这两个函数都不是必需的)。访问器属性有如下 4 个特性。
[[Configurable]]
[[Enumerable]]
[[Get]]
[[Set]]
访问器属性不能直接定义,必须使用 Object.defineProperty() 来定义。
var book = {
_year: 2004,
edition: 1
};
Object.defineProperty(book, "year", {
get: function(){
return this._year;
},
set: function(newValue){
if (newValue > 2004) {
this._year = newValue;
this.edition += newValue - 2004;
}
}
});
book.year = 2005;
alert(book.edition); //2
ECMAScript 5 定义了一个 Object.defineProperties() 方法。利用这个方法可以通过描述符一次定义多个属性。 使用 ECMAScript 5 的 Object.getOwnPropertyDescriptor() 方法,可以取得给定属性的描述符。
有哪些创建JavaScript对象的模式?各有什么利弊?
工厂模式
function createPerson(name, age, job){
var o = new Object();
o.name = name;
o.age = age;
o.job = job;
o.sayName = function(){
alert(this.name);
};
return o;
}
var person = createPerson("Nicholas", 29, "Software Engineer");
var person2 = createPerson("Greg", 27, "Doctor");
工厂模式虽然解决了创建多个相似对象的问题,但却没有解决对象识别的问题(即怎样知道一个对象的类型)。
构造函数模式
function Person(name, age, job){ // 没有 return 语句
this.name = name;
this.age = age;
this.job = job;
this.sayName = function(){
alert(this.name);
};
}
var person1 = new Person("Nicholas", 29, "Software Engineer");
var person2 = new Person("Greg", 27, "Doctor");
alert(person1.constructor == Person); //true
alert(person2.constructor == Person); //true
以new 操作符调用构造函数实际上会经历以下 4个步骤: (1) 创建一个新对象; (2) 将构造函数的作用域赋给新对象(因此 this 就指向了这个新对象); (3) 执行构造函数中的代码(为这个新对象添加属性); (4) 返回新对象。
任何函数,只要通过 new 操作符来调用,那它就可以作为构造函数;如果不通过 new 操作符来调用,那它跟普通函数也不会有什么两样。 使用构造函数的主要问题,就是每个方法都要在每个实例上重新创建一遍。
原型模式 每个函数都有一个 prototype (原型)属性,这个属性是一个指针,指向一个对象,而这个对象的用途是包含可以由特定类型的所有实例共享的属性和方法。
function Person(){
}
Person.prototype.name = "Nicholas";
Person.prototype.age = 29;
Person.prototype.job = "Software Engineer";
Person.prototype.sayName = function(){
alert(this.name);
};
var person1 = new Person();
person1.sayName(); //"Nicholas"
var person2 = new Person();
person2.sayName(); //"Nicholas"
alert(person1.sayName == person2.sayName); //true
寄生构造函数模式 基本思想是创建一个函数,该函数的作用仅仅是封装创建对象的代码,然后再返回新创建的对象;但从表面上看,这个函数又很像是典型的构造函数。返回的对象与构造函数或者与构造函数的原型属性之间没有关系;也就是说,构造函数返回的对象与在构造函数外部创建的对象没有什么不同。为此,不能依赖 instanceof 操作符来确定对象类型。由于存在上述问题,建议在可以使用其他模式的情况下,不要使用这种模式。
function Person(name, age, job){
var o = new Object();
o.name = name;
o.age = age;
o.job = job;
o.sayName = function(){
alert(this.name);
};
return o;
}
var friend = new Person("Nicholas", 29, "Software Engineer");
friend.sayName(); //"Nicholas"
稳妥构造函数模式 所谓稳妥对象,指的是没有公共属性,而且其方法也不引用 this 的对象。 稳妥构造函数遵循与寄生构造函数类似的模式,但有两点不同:一是新创建对象的实例方法不引用 this ;二是不使用 new 操作符调用构造函数。
function Person(name, age, job){
//创建要返回的对象
var o = new Object();
//可以在这里定义私有变量和函数
//添加方法
o.sayName = function(){
alert(name);
};
//返回对象
return o;
}
var friend = Person("Nicholas", 29, "Software Engineer");
friend.sayName(); //"Nicholas" 除了使用 sayName() 方法之外,没有其他办法访问 name 的值
使用稳妥构造函数模式创建的对象与构造函数之间也没有什么关系,因此 instanceof 操作符对这种对象也没有意义
构造函数、构造函数的原型对象以及构造函数的实例,相互之间是什么关系?
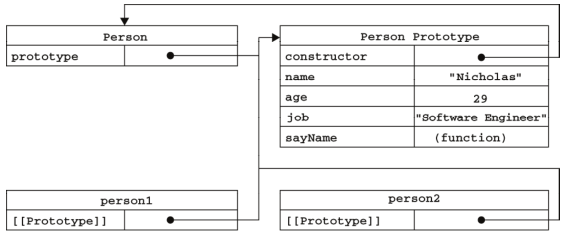 无论什么时候,只要创建了一个新函数,就会根据一组特定的规则为该函数创建一个 prototype属性,这个属性指向函数的原型对象。
在默认情况下,所有原型对象都会自动获得一个 constructor属性,这个属性包含一个指向 prototype 属性所在函数的指针。
当调用构造函数创建一个新实例后,该实例的内部将包含一个指针,指向构造函数的原型对象。ECMA-262 第 5 版中管这个指针叫 [[Prototype]] ,Firefox、Safari 和 Chrome 在每个对象上都支持一个属性__proto__用来访问这个指针。可以通过 isPrototypeOf() 方法来确定对象之间是否存在这种关系:
无论什么时候,只要创建了一个新函数,就会根据一组特定的规则为该函数创建一个 prototype属性,这个属性指向函数的原型对象。
在默认情况下,所有原型对象都会自动获得一个 constructor属性,这个属性包含一个指向 prototype 属性所在函数的指针。
当调用构造函数创建一个新实例后,该实例的内部将包含一个指针,指向构造函数的原型对象。ECMA-262 第 5 版中管这个指针叫 [[Prototype]] ,Firefox、Safari 和 Chrome 在每个对象上都支持一个属性__proto__用来访问这个指针。可以通过 isPrototypeOf() 方法来确定对象之间是否存在这种关系:
alert(Person.prototype.isPrototypeOf(person1)); //true
alert(Person.prototype.isPrototypeOf(person2)); //true
ECMAScript 5 增加了一个新方法,叫 Object.getPrototypeOf() ,在所有支持的实现中,这个方法返回 [[Prototype]] 的值。例如:
alert(Object.getPrototypeOf(person1) == Person.prototype); //true
alert(Object.getPrototypeOf(person1).name); //"Nicholas"
如何判断对象属性的定义位置?
每当代码读取某个对象的某个属性时,都会执行一次搜索,目标是具有给定名字的属性。搜索首先从对象实例本身开始。如果在实例中找到了具有给定名字的属性,则返回该属性的值;如果没有找到,则继续搜索指针指向的原型对象,在原型对象中查找具有给定名字的属性。如果在原型对象中找到了这个属性,则返回该属性的值。
虽然可以通过对象实例访问保存在原型中的值,但却不能通过对象实例重写原型中的值。
当为对象实例添加一个属性时,这个属性就会屏蔽原型对象中保存的同名属性。使用 delete 操作符则可以完全删 除实例属性,从而让我们能够重新访问原型中的属性。
使用 hasOwnProperty() 方法可以检测一个属性是存在于实例中,还是存在于原型中。这个方法(从 Object 继承来的)只在给定属性存在于对象实例中时,才会返回 true 。
Object.getOwnPropertyDescriptor() 方法只能用于实例属性,要取得原型属性的描述符,必须直接在原型对象上调用 Object.getOwnPropertyDescriptor() 方法。
in 操作符会在通过对象能够访问给定属性时返回 true ,无论该属性存在于实例中还是原型中。因此只要 in 操作符返回 true 而 hasOwnProperty() 返回 false ,就可以确定属性是原型中的属性。
在使用 for-in 循环时,返回的是所有能够通过对象访问的、可枚举的(enumerated)属性,其中既包括存在于实例中的属性,也包括存在于原型中的属性。屏蔽了原型中不可枚举属性(即将[[Enumerable]] 标记为 false 的属性)的实例属性也会在 for-in 循环中返回,因为根据规定,所有开发人员定义的属性都是可枚举的。
要取得对象上所有可枚举的实例属性,可以使用 ECMAScript 5 的 Object.keys() 方法。
基于原型链实现继承的原理是什么?存在什么问题?
许多 OO 语言都支持两种继承方式:接口继承和实现继承。接口继承只继承方法签名,而实现继承则继承实际的方法。由于函数没有签名,在 ECMAScript 中无法实现接口继承。ECMAScript 只支持实现继承,而且其实现继承主要是依靠原型链来实现的。 其基本思想是利用原型让一个引用类型继承另一个引用类型的属性和方法。基本如下:
function SuperType(){
this.property = true;
}
SuperType.prototype.getSuperValue = function(){
return this.property;
};
function SubType(){
this.subproperty = false;
}
//继承了 SuperType
SubType.prototype = new SuperType();
SubType.prototype.getSubValue = function (){
return this.subproperty;
};
var instance = new SubType();
alert(instance.getSuperValue()); //true
SubType 继承了 SuperType ,而继承是通过创建 SuperType 的实例,并将该实例赋给SubType.prototype 实现的。实现的本质是重写原型对象,代之以一个新类型的实例。原来存在于 SuperType 的实例中的所有属性和方法,现在也存在于 SubType.prototype 中了。
要注意 instance.constructor 现在指向的是 SuperType ,这是因为原来 SubType.prototype 中的 constructor 被重写了的缘故. 实际上,不是 SubType 的原型的 constructor 属性被重写了,而是 SubType 的原型指向了另一个对象SuperType 的原型,而这个原型对象的 constructor 属性指向的是 SuperType 。
所有函数的默认原型都是 Object 的实例,因此默认原型都会包含一个内部指针,指向 Object.prototype 。这也正是所有自定义类型都会继承 toString() 、valueOf() 等默认方法的根本原因。
继承关系判断 使用 instanceof 操作符,只要用这个操作符来测试实例与原型链中出现过的构造函数,结果就会返回 true :
alert(instance instanceof Object); //true
alert(instance instanceof SuperType); //true
alert(instance instanceof SubType); //true
使用 isPrototypeOf() 方法。同样,只要是原型链中出现过的原型,都可以说是该原型链所派生的实例的原型,因此 isPrototypeOf() 方法也会返回 true:
alert(Object.prototype.isPrototypeOf(instance)); //true
alert(SuperType.prototype.isPrototypeOf(instance)); //true
alert(SubType.prototype.isPrototypeOf(instance)); //true
原型链最主要的问题来自包含引用类型值的原型。第二个问题是:在创建子类型的实例时,不能向超类型的构造函数中传递参数。
JavaScript中有哪些实现继承的方式?
借用构造函数 在子类型构造函数的内部调用超类型构造函数:
function SuperType(){
this.colors = ["red", "blue", "green"];
}
function SubType(){
SuperType.call(this);
}
var instance1 = new SubType();
instance1.colors.push("black");
alert(instance1.colors); //"red,blue,green,black"
var instance2 = new SubType();
alert(instance2.colors); //"red,blue,green"
借用构造函数有一个很大的优势,即可以在子类型构造函数中向超类型构造函数传递参数:
function SuperType(name){
this.name = name;
}
function SubType(){
SuperType.call(this, "Nicholas");
this.age = 29; // 实例属性
}
var instance = new SubType();
alert(instance.name); //"Nicholas";
alert(instance.age); //29
如果仅仅是借用构造函数,那么也将无法避免构造函数模式存在的问题——方法都在构造函数中定义,因此函数复用就无从谈起了。
组合继承 也叫做伪经典继承,指的是将原型链和借用构造函数的技术组合到一块,从而发挥二者之长的一种继承模式。思路是使用原型链实现对原型属性和方法的继承,而通过借用构造函数来实现对实例属性的继承。 组合继承最大的问题就是无论什么情况下,都会调用两次超类型构造函数:一次是在创建子类型原型的时候,另一次是在子类型构造函数内部:
function SuperType(name){
this.name = name;
this.colors = ["red", "blue", "green"];
}
SuperType.prototype.sayName = function(){
alert(this.name);
};
function SubType(name, age){
SuperType.call(this, name); // 第二次调用 SuperType()
this.age = age;
}
SubType.prototype = new SuperType(); // 第一次调用 SuperType()
SubType.prototype.constructor = SubType;
SubType.prototype.sayAge = function(){
alert(this.age);
};
当调用 SubType 构造函数时,又会调用一次 SuperType 构造函数,这一次又在新对象上创建了实例属性 name 和 colors 。于是,这两个属性就屏蔽了原型中的两个同名属性。
原型式继承
function object(o){
function F(){
}
F.prototype = o;
return new F();
}
ECMAScript 5 通过新增 Object.create() 方法规范化了原型式继承。这个方法接收两个参数:一个用作新对象原型的对象和(可选的)一个为新对象定义额外属性的对象。在传入一个参数的情况下,Object.create() 与 object() 方法的行为相同。
var person = {
name: "Nicholas",
friends: ["Shelby", "Court", "Van"]
};
var anotherPerson = Object.create(person, {
name: {
value: "Greg"
}
});
alert(anotherPerson.name); //"Greg"
寄生式继承 创建一个仅用于封装继承过程的函数,该函数在内部以某种方式来增强对象,最后再像真地是它做了所有工作一样返回对象。
function createAnother(original){
var clone = object(original); //通过调用函数创建一个新对象
clone.sayHi = function(){ //以某种方式来增强这个对象
alert("hi");
};
return clone; //返回这个对象
}
使用寄生式继承来为对象添加函数,会由于不能做到函数复用而降低效率;这一点与构造函数模式类似。
寄生组合式继承 所谓寄生组合式继承,即通过借用构造函数来继承属性,通过原型链的混成形式来继承方法。其背后的基本思路是:不必为了指定子类型的原型而调用超类型的构造函数,我们所需要的无非就是超类型原型的一个副本而已。本质上,就是使用寄生式继承来继承超类型的原型,然后再将结果指定给子类型的原型。寄生组合式继承的基本模式如下所示。
function inheritPrototype(subType, superType){
var prototype = object(superType.prototype); //创建对象
prototype.constructor = subType; //增强对象
subType.prototype = prototype; //指定对象
}
function SuperType(name){
this.name = name;
this.colors = ["red", "blue", "green"];
}
SuperType.prototype.sayName = function(){
alert(this.name);
};
function SubType(name, age){
SuperType.call(this, name);
this.age = age;
}
inheritPrototype(SubType, SuperType);
SubType.prototype.sayAge = function(){
alert(this.age);
};
这个例子的高效率体现在它只调用了一次 SuperType 构造函数,并且因此避免了在 SubType.prototype 上面创建不必要的、多余的属性。与此同时,原型链还能保持不变;因此,还能够正常使用instanceof 和 isPrototypeOf() 。开发人员普遍认为寄生组合式继承是引用类型最理想的继承范式。 YUI 的 YAHOO.lang.extend() 方法采用了寄生组合继承,从而让这种模式首次出现在了一个应用非常广泛的 JavaScript 库中。
什么是闭包?闭包的实现原理是什么?存在什么问题?
闭包是指有权访问另一个函数作用域中的变量的函数,创建闭包的常见方式,就是在一个函数内部创建另一个函数。
当某个函数被调用时,会创建一个执行环境(execution context)及相应的作用域链。然后,使用 arguments 和其他命名参数的值来初始化函数的活动对象(activation object)。但在作用域链中,外部函数的活动对象始终处于第二位,外部函数的外部函数的活动对象处于第三位,……直至作为作用域链终点的全局执行环境。在函数执行过程中,为读取和写入变量的值,就需要在作用域链中查找变量。
后台的每个执行环境都有一个表示变量的对象——变量对象。全局环境的变量对象始终存在,而自定义函数的局部环境的变量对象,则只在函数执行的过程中存在。在创建函数时,会创建一个预先包含全局变量对象的作用域链,这个作用域链被保存在内部的 [[Scope]] 属性中。当调用函数时,会为函数创建一个执行环境,然后通过复制函数的 [[Scope]] 属性中的对象构建起执行环境的作用域链。此后,又有一个活动对象(在此作为变量对象使用)被创建并被推入执行环境作用域链的前端。
作用域链本质上是一个指向变量对象的指针列表,它只引用但不实际包含变量对象。无论什么时候在函数中访问一个变量时,就会从作用域链中搜索具有相应名字的变量。一般来讲,当函数执行完毕后,局部活动对象就会被销毁,内存中仅保存全局作用域(全局执行环境的变量对象)。但是,闭包的情况又有所不同。在另一个函数内部定义的函数(包括匿名函数)会将包含函数(即外部函数)的活动对象添加到它的作用域链中。在匿名函数从包含函数中被返回后,它的作用域链被初始化为包含函数的活动对象和全局变量对象。这样,匿名函数就可以访问在包含函数中定义的所有变量。更为重要的是,包含函数在执行完毕后,其活动对象也不会被销毁,因为匿名函数的作用域链仍然在引用这个活动对象。换句话说,当包含函数返回后,其执行环境的作用域链会被销毁,但它的活动对象仍然会留在内存中;直到匿名函数被销毁后,包含函数的活动对象才会被销毁。
作用域链的这种配置机制引出了一个值得注意的副作用,即闭包只能取得包含函数中任何变量的最后一个值。
function createFunctions(){
var result = new Array();
for (var i=0; i < 10; i++){
result[i] = function(){
return i;
};
}
return result;
}
每个函数都返回 10。因为每个函数的作用域链中都保存着 createFunctions() 函数的活动对象,所以它们引用的都是同一个变量 i 。当createFunctions() 函数返回后,变量 i 的值是 10,此时每个函数都引用着保存变量 i 的同一个变量对象,所以在每个函数内部 i 的值都是 10。 可以通过创建另一个匿名函数强制让闭包的行为 符合预期:
function createFunctions(){
var result = new Array();
for (var i=0; i < 10; i++){
result[i] = function(num){
return function(){
return num;
};
}(i);
}
return result;
}
匿名函数的中的this指向哪里?
this 对象是在运行时基于函数的执行环境绑定的:在全局函数中, this 等于 window ,而当函数被作为某个对象的方法调用时, this 等于那个对象。不过,匿名函数的执行环境具有全局性,因此其 this 对象通常指向 window。
var name = "The Window";
var object = {
name : "My Object",
getNameFunc : function(){
return function(){
return this.name;
};
}
};
alert(object.getNameFunc()()); //"The Window"(在非严格模式下)
把外部作用域中的 this 对象保存在一个闭包能够访问到的变量里,就可以让闭包访问该对象了
var name = "The Window";
var object = {
name : "My Object",
getNameFunc : function(){
var that = this;
return function(){
return that.name;
};
}
};
alert(object.getNameFunc()()); //"My Object"
如何使用匿名函数来模仿块级作用域?
(function(){
//这里是块级作用域
})();
将函数声明包含在一对圆括号中,表示它实际上是一个函数表达式。
function outputNumbers(count){
(function () {
for (var i=0; i < count; i++){
alert(i);
}
})();
alert(i); //导致一个错误!
}
在匿名函数中定义的任何变量,都会在执行结束时被销毁。因此,变量 i 只能在循环中使用,使用后即被销毁。而在私有作用域中能够访问变量 count ,是因为这个匿名函数是一个闭包,它能够访问包含作用域中的所有变量。 这种技术经常在全局作用域中被用在函数外部,从而限制向全局作用域中添加过多的变量和函数。
JavaScript中的DOM节点有哪些类型?DOM节点有哪些属性和方法?
JavaScript 中的所有节点类型都继承自Node 类型,因此所有节点类型都共享着相同的基本属性和方法。每个节点都有一个 nodeType 属性,用于表明节点的类型。节点类型由在 Node 类型中定义的下列12 个数值常量来表示(即一共有12种节点类型):
Node.ELEMENT_NODE (1);
Node.ATTRIBUTE_NODE (2);
Node.TEXT_NODE (3);
Node.CDATA_SECTION_NODE (4);
Node.ENTITY_REFERENCE_NODE (5);
Node.ENTITY_NODE (6);
Node.PROCESSING_INSTRUCTION_NODE (7);
Node.COMMENT_NODE (8);
Node.DOCUMENT_NODE (9);
Node.DOCUMENT_TYPE_NODE (10);
Node.DOCUMENT_FRAGMENT_NODE (11);
Node.NOTATION_NODE (12);
并不是所有节点类型都受到 Web 浏览器的支持。
nodeType // 节点类型
nodeName // 元素的标签名
nodeValue //
childNodes // 保存着一个NodeList对象(类数组对象,有length属性,可以用[]访问,但是不是数组)。NodeList 对象的独特之处在于,它实际上是基于 DOM 结构动态执行查询的结果,因此 DOM 结构的变化能够自动反映在 NodeList 对象中。父节点的 firstChild 和 lastChild属性分别指向其 childNodes 列表中的第一个和最后一个节点。
一般来说,应该尽量减少访问 NodeList 的次数。因为每次访问 NodeList ,都会运行一次基于文档的查询。所以,可以考虑将从 NodeList 中取得的值缓存起来。
parentNode //
ownerDocument // 指向表示整个文档的文档节点
hasChildNodes()
appendChild() // 向 childNodes 列表的末尾添加一个节点。如果传入到 appendChild() 中的节点已经是文档的一部分了,那结果就是将该节点从原来的位置转移到新位置。任何 DOM 节点不能同时出现在文档中的多个位置上。因此,如果在调用 appendChild() 时传入了父节点的第一个子节点,那么该节点就会成为父节点的最后一个子节点。
insertBefore()
replaceChild()
removeChild()
cloneNode() //接受一个布尔值参数,表示是否执行深复制。不会复制添加到 DOM 节点中的 JavaScript 属性,例如事件处理程序等。这个方法只复制特性、(在明确指定的情况下也复制)子节点,其他一切都不会复制。
normalize() // 处理文档树中的文本节点,由于解析器的实现或 DOM 操作等原因,可能会出现文本节点不包含文本,或者接连出现两个文本节点的情况。当在某个节点上调用这个方法时,就会在该节点的后代节点中查找上述两种情况。如果找到了空文本节点,则删除它;如果找到相邻的文本节点,则将它们合并为一个文本节点。
document对象的类型是什么?有哪些属性和方法?
document 对象是 HTMLDocument (继承自Document类型)的一个实例,表示整个 HTML 页面。而且, document 对象是 window 对象的一个属性,因此可以将其作为全局对象来访问。
nodeType 的值为 9
nodeName 的值为 "#document"
nodeValue 的值为 null
parentNode 的值为 null
documentElement // 该属性始终指向 HTML 页面中的 <html> 元素
body // 直接指向 <body> 元素
doctype // 取得对<!DOCTYPE>的引用
title //包含着<title> 元素中的文本,修改 title 属性的值不会改变 <title>元素
URL // 页面完整的 URL
domain // 页面的域名
当页面中包含来自其他子域的框架或内嵌框架时,能够设置 document.domain 就非常方便了。由
于 跨 域 安 全 限 制 , 来 自 不 同 子 域 的 页 面 无 法 通 过 JavaScript 通 信 。 而 通 过 将 每 个 页 面 的document.domain 设置为相同的值,这些页面就可以互相访问对方包含的 JavaScript 对象了。例如,假设有一个页面加载自 www.wrox.com,其中包含一个内嵌框架,框架内的页面加载自 p2p.wrox.com。由于 document.domain 字符串不一样,内外两个页面之间无法相互访问对方的 JavaScript 对象。但如果将这两个页面的 document.domain 值都设置为 "wrox.com" ,它们之间就可以通信了。
referrer // 链接到当前页面的那个页面的 URL
document.anchors // 文档中所有带 name 特性的 <a> 元素
document.forms // 文档中所有的 <form> 元素,与 document.getElementsByTagName("form")得到的结果相同
getElementById() // 如果页面中多个元素的 ID 值相同,只返回文档中第一次出现的元素
document.links // 包含文档中所有带 href 特性的 <a> 元素
implementation // 检测浏览器实现了 DOM 的哪些部分
getElementsByTagName() // 返回一个 HTMLCollection 对象,作为一个“动态”集合,该对象与 NodeList 非常类似
getElementsByName()
createElement()
所有 HTML 元素都是由 HTMLElement 或者其更具体的子类型来表示的。如:
A HTMLAnchorElement
BODY HTMLBodyElement
BUTTON HTMLButtonElement
DIV HTMLDivElement
有哪些对DOM的扩展?
Selectors API:由 W3C 发起制定的一个标准,致力于让浏览器原生支持 CSS 查询。 HTML5:围绕如何使用新增标记定义了大量 JavaScript API。其中一些 API 与 DOM 重叠,定义了浏览器应该支持的 DOM扩展。 此外不同浏览器有自己的专有扩展。
有哪些为元素定义事件的方式?
HTML事件处理程序:
<input type="button" value="Click Me" onclick="alert('Clicked')" />
DOM0 级事件处理程序:
var btn = document.getElementById("myBtn");
btn.onclick = function(){
alert("Clicked");
};
btn.onclick = null; //删除事件处理程序
```javascript
以这种方式添加的事件处理程序会在事件流的冒泡阶段被处理。
DOM2 级事件处理程序:
```javascript
var btn = document.getElementById("myBtn");
btn.addEventListener("click", function(){
alert(this.id);
}, false);
// 可以添加多个事件处理程序,它们将按顺序触发
btn.addEventListener("click", function(){
alert("Hello world!");
}, false);
通过 addEventListener() 添加的事件处理程序只能使用 removeEventListener() 来移除;移除时传入的参数与添加处理程序时使用的参数相同。这也意味着通过 addEventListener() 添加的匿名函数将无法移除。
大多数情况下,都是将事件处理程序添加到事件流的冒泡阶段,这样可以最大限度地兼容各种浏览器。最好只在需要在事件到达目标之前截获它的时候将事件处理程序添加到捕获阶段。如果不是特别需要,不建议在事件捕获阶段注册事件处理程序。
event对象有哪些属性和方法?currentTarget和target有什么区别?
在触发 DOM 上的某个事件时,会产生一个事件对象 event(无论指定事件处理程序时使用什 么方法)
btn.onclick = function(event){
alert(event.type); //"click"
};
btn.addEventListener("click", function(event){
alert(event.type); //"click"
}, false);
event 对象包含与创建它的特定事件有关的属性和方法。触发的事件类型不一样,可用的属性和方 法也不一样。不过,有一些公共的成员:
bubbles 表明事件是否冒泡
cancelable 表明是否可以取消事件的默认行为
currentTarget 其事件处理程序当前正在处理事件的那个元素
defaultPrevented 为 true 表 示 已 经 调 用 了 preventDefault()
preventDefault() 取消事件的默认行为。如果 cancelable 是true ,则可以使用这个方法
stopImmediatePropagation() 取消事件的进一步捕获或冒泡,同时阻止任何事件处理程序被调用
stopPropagation() 取消事件的进一步捕获或冒泡。如果 bubbles为 true ,则可以使用这个方法
target 事件的目标
trusted 为 true 表示事件是浏览器生成的。为 false 表示 事 件 是 由 开 发 人 员 通 过 JavaScript 创 建 的
type 被触发的事件的类型
view 与事件关联的抽象视图。等同于发生事件的window 对象
eventPhase 事件当前正位于事件流的哪个阶段。捕获阶段eventPhase为1 ;事件处理程序处于目标对象上,为2 ;在冒泡阶段调用的事件处理程序,为3 。要注意的是,尽管“处于目标”发生在冒泡阶段,但 eventPhase 仍然一直等于 2 。
在事件处理程序内部,对象 this 始终等于 currentTarget 的值,而 target 则只包含事件的实际目标。如果直接将事件处理程序指定给了目标元素,则 this 、 currentTarget 和 target 包含相同的值:
var btn = document.getElementById("myBtn");
btn.onclick = function(event){
alert(event.currentTarget === this); //true
alert(event.target === this); //true
};
如果事件处理程序存在于按钮的父节点中(例如 document.body ),那么这些值是不相同的:
document.body.onclick = function(event){
alert(event.currentTarget === document.body); //true
alert(this === document.body); //true
alert(event.target === document.getElementById("myBtn")); //true
};
this 和 currentTarget 都等于 document.body ,因为事件处理程序是注册到这个元素上的。然而, target 元素却等于按钮元素,因为它是 click 事件真正的目标。由于按钮上并没有注册事件处理程序,结果 click 事件就冒泡到了 document.body ,在那里事件才得到了处理。
如何优化因为定义事件而带来的性能问题?
在 JavaScript 中,添加到页面上的事件处理程序数量将直接关系到页面的整体运行性能。导致这一问题的原因是多方面的:
每个函数都是对象,都会占用内存;内存中的对象越多,性能就越差。
必须事先指定所有事件处理程序而导致的 DOM访问次数,会延迟整个页面的交互就绪时间。
每当将事件处理程序指定给元素时,运行中的浏览器代码与支持页面交互的 JavaScript 代码之间就会建立一个连接。这种连接越多,页面执行起来就越慢。内存中留有那些过时不用的“空事件处理程序”(dangling event handler),也是造成 Web 应用程序内存与性能问题的主要原因。在两种情况下,可能会造成上述问题。第一种情况就是从文档中移除带有事件处理程序的元素时。这可能是通过纯粹的 DOM 操作,例如使用 removeChild() 和 replaceChild() 方法,但更多地是发生在使用 innerHTML 替换页面中某一部分的时候。如果带有事件处理程序的元素被 innerHTML 删除了,那么原来添加到元素中的事件处理程序极有可能无法被当作垃圾回收。
事件委托 利用事件冒泡,只指定一个事件处理程序,就可以管理某一类型的所有事件。例如, click 事件会一直冒泡到 document 层次。也就是说,可以为整个页面指定一个 onclick 事件处理程序(然后通过类似switch(target.id)的判断来确定具体要执行的操作,而不必给每个可单击的元素分别添加事件处理程序。 因为只取得了一个 DOM 元素,只添加了一个事件处理程序。虽然对用户来说最终的结果相同,但这种技术需要占用的内存更少。所有用到按钮的事件(多数鼠标事件和键盘事件)都适合采用事件委托技术。
如何触发模拟事件?如何自定义事件?
可以使用 JavaScript 在任意时刻来触发特定的事件,而此时的事件就如同浏览器创建的事件一样:该冒泡还会冒泡,而且照样能够导致浏览器执行已经指定的处理它们的事件处理程序。
可以在 document 对象上使用createEvent()方法创建 event 对象。这个方法接收一个参数,即表示要创建的事件类型的字符串。在 DOM2 级中,所有这些字符串都使用英文复数形式,而在 DOM3级中都变成了单数。这个字符串可以是下列几字符串之一。
UIEvents :一般化的 UI 事件。鼠标事件和键盘事件都继承自 UI 事件。DOM3 级中是 UIEvent 。
MouseEvents :一般化的鼠标事件。DOM3 级中是 MouseEvent 。
MutationEvents :一般化的 DOM 变动事件。DOM3 级中是 MutationEvent 。
HTMLEvents :一般化的 HTML 事件。没有对应的 DOM3 级事件(HTML 事件被分散到其他类别中)。
模拟事件的最后一步就是触发事件。这一步需要使用dispatchEvent() 方法,所有支持事件的DOM 节点都支持这个方法。调用 dispatchEvent() 方法时,需要传入一个参数,即表示要触发事件的 event 对象。
DOM3 级还定义了“自定义事件”。自定义事件不是由 DOM 原生触发的,它的目的是让开发人员创建自己的事件。要创建新的自定义事件,可以调用 createEvent(“CustomEvent”) 。返回的对象有一个名为 initCustomEvent() 的方法,接收如下 4 个参数: type (字符串):触发的事件类型,例如 “keydown” 。 bubbles (布尔值):表示事件是否应该冒泡。 cancelable (布尔值):表示事件是否可以取消。 detail (对象):任意值,保存在 event 对象的 detail 属性中。 可以像分派其他事件一样在 DOM 中分派创建的自定义事件对象。例如:
var div = document.getElementById("myDiv");
EventUtil.addHandler(div, "myevent", function(event){
alert("DIV: " + event.detail);
});
EventUtil.addHandler(document, "myevent", function(event){
alert("DOCUMENT: " + event.detail);
});
if (document.implementation.hasFeature("CustomEvents", "3.0")){
event = document.createEvent("CustomEvent");
event.initCustomEvent("myevent", true, false, "Hello world!");
div.dispatchEvent(event);
}
有哪些提交表单、重置表单的方式?
用户单击提交按钮时,就会提交表单。使用 <input> 或 <button> 都可以定义提交按钮,只要将其 type 特性的值设置为 “submit” 即可。以这种方式提交表单时,浏览器会在将请求发送给服务器之前触发 submit 事件。这样就有机会验证表单数据,并据以决定是否允许表单提交。
在 JavaScript 中,以编程方式调用 submit() 方法也可以提交表单。而且,这种方式无需表单包含
var form = document.getElementById("myForm");
// 提交表单
form.submit();
在以调用 submit() 方法的形式提交表单时,不会触发 submit 事件,因此要记得在调用此方法之前先验证表单数据。
重置与提交类似:
使用 type 特性值为 “reset” 的 <input> 或 <button> 都可以创建重置按钮。
也可以通过 JavaScript 来重置表单:
var form = document.getElementById("myForm");
// 重置表单
form.reset();
与调用 submit() 方法不同,调用 reset() 方法会像单击重置按钮一样触发 reset 事件。
在表单提交时,浏览器是怎样组织数据并发送给服务器的?
对表单字段的名称和值进行 URL 编码,使用和号(&)分隔。
不发送禁用的表单字段。
只发送勾选的复选框和单选按钮。
不发送 type 为 “reset” 和 “button” 的按钮。
多选选择框中的每个选中的值单独一个条目。
在单击提交按钮提交表单的情况下,也会发送提交按钮;否则,不发送提交按钮。也包括 type为 “image” 的 <input> 元素。
<select> 元素的值,就是选中的 <option> 元素的 value 特性的值。如果 <option> 元素没有value 特性,则是 <option> 元素的文本值。
富文本编辑的原理是什么?
在页面中嵌入一个包含空 HTML 页面的 iframe 。通过设置designMode 属性,这个空白的 HTML 页面可以被编辑,而编辑对象则是该页面 <body> 元素的 HTML 代码。 designMode 属性有两个可能的值: “off” (默认值)和 “on” 。在设置为 “on” 时,整个文档都会变得可以编辑(显示插入符号),然后就可以像使用字处理软件一样,通过键盘将文本内容加粗、变成斜体,等等。
另一种编辑富文本内容的方式是使用名为 contenteditable 的特殊属性,这个属性也是由 IE 最早实现的。可以把 contenteditable 属性应用给页面中的任何元素,然后用户立即就可以编辑该元素。这种方法之所以受到欢迎,是因为它不需要 iframe 、空白页和 JavaScript,只要为元素设置contenteditable 属性即可。
<div class="editable" id="richedit" contenteditable></div>
这样,元素中包含的任何文本内容就都可以编辑了,就好像这个元素变成了 <textarea> 元素一样。
与富文本编辑器交互的主要方式,就是使用 document.execCommand() 。这个方法可以对文档执行预定义的命令(加粗、拷贝、剪切、缩进等等),而且可以应用大多数格式。
Ajax和Comet的区别是什么?Comet有哪些实现方式?
Ajax 是一种从页面向服务器请求数据的技术,而 Comet 则是一种服务器向页面推送数据的技 术。Comet 能够让信息近乎实时地被推送到页面上。
有两种实现 Comet 的方式:长轮询和流。 长轮询把短轮询颠倒了一下。页面发起一个到服务器的请求,然后服务器一直保持连接打开,直到有数据可发送。发送完数据之后,浏览器关闭连接,随即又发起一个到服务器的新请求。这一过程在页面打开期间一直持续不断。 无论是短轮询还是长轮询,浏览器都要在接收数据之前,先发起对服务器的连接。两者最大的区别在于服务器如何发送数据。短轮询是服务器立即发送响应,无论数据是否有效,而长轮询是等待发送响应。轮询的优势是所有浏览器都支持,因为使用 XHR 对象和 setTimeout() 就能实现。
第二种流行的 Comet 实现是 HTTP 流。流不同于上述两种轮询,因为它在页面的整个生命周期内只使用一个 HTTP 连接。具体来说,就是浏览器向服务器发送一个请求,而服务器保持连接打开,然后周期性地向浏览器发送数据。 比如,下面这段 PHP 脚本就是采用流实现的服务器中常见的形式。
<?php
$i = 0;
while(true){
//输出一些数据,然后立即刷新输出缓存
echo "Number is $i";
flush();
//等几秒钟
sleep(10);
$i++;
}
所有服务器端语言都支持打印到输出缓存然后刷新(将输出缓存中的内容一次性全部发送到客户端)的功能。而这正是实现HTTP流的关键所在。 在 Firefox、Safari、Opera 和 Chrome 中,通过侦听 readystatechange 事件及检测 readyState的值是否为 3,就可以利用 XHR 对象实现 HTTP 流。在上述这些浏览器中,随着不断从服务器接收数据, readyState 的值会周期性地变为 3。当 readyState 值变为 3 时, responseText 属性中就会保存接收到的所有数据。此时,就需要比较此前接收到的数据,决定从什么位置开始取得最新的数据。
Websocket的建立流程是怎样的?它有哪些优缺点?
Web Sockets的目标是在一个单独的持久连接上提供全双工、双向通信。
要创建 Web Socket,先实例一个 WebSocket 对象并传入要连接的 URL:
var socket = new WebSocket("ws://www.example.com/server.php");
socket.send("Hello world!");
socket.close();
注意,必须给 WebSocket 构造函数传入绝对 URL。同源策略对 Web Sockets 不适用,因此可以通过它打开到任何站点的连接。
实例化了 WebSocket 对象后,浏览器就会马上尝试创建连接。
因为 Web Sockets只能通过连接发送纯文本数据,所以对于复杂的数据结构,在通过连接发送之前,必须进行序列化。
在 JavaScript 中创建了 Web Socket 之后,会有一个 HTTP 请求发送到浏览器以发起连接。在取得服务器响应后,建立的连接会使用 HTTP 升级从 HTTP 协议交换为 WebSocket 协议。也就是说,使用标准的 HTTP 服务器无法实现 Web Sockets,只有支持这种协议的专门服务器才能正常工作。 由于 Web Sockets使用了自定义的协议,所以 URL 模式也略有不同。未加密的连接不再是 http:// ,而是 ws:// ;加密的连接也不是 https:// ,而是 wss:// 。 使用自定义协议而非 HTTP 协议的好处是,能够在客户端和服务器之间发送非常少量的数据,而不必担心 HTTP 那样字节级的开销。由于传递的数据包很小,因此 Web Sockets非常适合移动应用。使用自定义协议的缺点在于,制定协议的时间比制定JavaScript API 的时间还要长。
什么是SSE?如何选择应该是用SSE还是Web Socket?
SSE(Server-Sent Events,服务器发送事件)是围绕只读 Comet 交互推出的 API 或者模式。SSE API用于创建到服务器的单向连接,服务器通过这个连接可以发送任意数量的数据。服务器响应的 MIME类型必须是 text/event-stream ,而且是浏览器中的 JavaScript API 能解析格式输出。SSE 支持短轮询、长轮询和 HTTP 流,而且能在断开连接时自动确定何时重新连接。
var source = new EventSource("myevents.php");
source.onmessage = function(event){
var data = event.data;
//处理数据
};
source.close();
所谓的服务器事件会通过一个持久的 HTTP 响应发送,这个响应的 MIME 类型为 text/event。 面对某个具体的用例,在考虑是使用 SSE 还是使用 Web Sockets 时,可以考虑如下几个因素: 首先,是否有自由度建立和维护 Web Sockets服务器?因为 Web Socket 协议不同于 HTTP,所以现有服务器 不能用于 Web Socket 通信。SSE 倒是通过常规 HTTP 通信,因此现有服务器就可以满足需求。 到底需不需要双向通信。如果用例只需读取服务器数据(如比赛成绩),那么 SSE 比较容易实现。如果用例必须双向通信(如聊天室),那么 Web Sockets 显然更好。(在不能选择 Web Sockets 的情况下,组合 XHR 和 SSE 也是能实现双向通信的)
如何区分原生与非原生JavaScript对象?
typeof 操作符经常会导致检测数据类型时得到不靠谱的结果。如Safari(直至第 4 版)在对正则表达式应用 typeof 操作符时会返回 “ function “ ,因此很难确定某个值到底是不是函数。
instanceof 操作符在存在多个全局作用域(像一个页面包含多个 frame)的情况下,也存在很多问题。一个经典的例子就是像下面这样将对象标识为数组:
var isArray = value instanceof Array;
以上代码要返回 true , value 必须是一个数组,而且还必须与 Array 构造函数在同个全局作用域中。(别忘了, Array 是 window 的属性。)如果 value 是在另个 frame 中定义的数组,那么以上代码就会返回 false 。
在任何值上调用 Object 原生的 toString() 方法,都会返回一个 [object NativeConstructorName] 格式的字符串。每个类在内部都有一个 [[Class]] 属性,这个属性中就指定了上述字符串中的构造函数名:
alert(Object.prototype.toString.call(value)); //”[object Array]”
由于原生数组的构造函数名与全局作用域无关,因此使用 toString() 就能保证返回一致的值。利用这一点,可以创建如下函数:
function isArray(value){
return Object.prototype.toString.call(value) == "[object Array]";
}
同样,也可以基于这一思路来测试某个值是不是原生函数或正则表达式:
function isFunction(value){
return Object.prototype.toString.call(value) == "[object Function]";
}
function isRegExp(value){
return Object.prototype.toString.call(value) == "[object RegExp]";
}
这一技巧也广泛应用于检测原生 JSON 对象。 Object 的 toString() 方法不能检测非原生构造函数的构造函数名。因此,开发人员定义的任何构造函数都将返回[object Object]。有些 JavaScript 库会包含与下面类似的代码。 var isNativeJSON = window.JSON && Object.prototype.toString.call(JSON) ==”[object JSON]”;
如何定义作用域安全的构造函数?
构造函数其实就是一个使用 new 操作符调用的函数。当使用 new 调用时,构造函数内用到的 this 对象会指向新创建的对象实例。当没有使用 new操作符来调用该构造函数的情况上。由于该 this 对象是在运行时绑定的,所以直接调用函数 ,this 会映射到全局对象 window 上,导致错误对象属性的意外增加。
function Person(name, age, job){
if (this instanceof Person){
this.name = name;
this.age = age;
this.job = job;
} else {
return new Person(name, age, job);
}
}
var person1 = Person("Nicholas", 29, "Software Engineer");
alert(window.name); //""
alert(person1.name); //"Nicholas"
var person2 = new Person("Shelby", 34, "Ergonomist");
alert(person2.name); //"Shelby"
如何阻止向对象中添加属性和方法?
默认情况下,所有对象都是可以扩展的。也就是说,任何时候都可以向对象中添加属性和方法。使用Object.preventExtensions()方法可以改变这个行为,使得不能再给对象添加属性和方法:
var person = { name: "Nicholas" };
alert(Object.isExtensible(person)); //true
Object.preventExtensions(person);
person.age = 29;
alert(person.age); //undefined
什么是密封对象?它有哪些特性?
密封对象不可扩展,而且已有成员的 [[Configurable]] 特性将被设置为 false 。这就意味着不能删除属性和方法,因为不能使用 Object.defineProperty() 把数据属性修改为访问器属性,或者相反。属性值是可以修改的。
要密封对象,可以使用 Object.seal()方法。
var person = { name: "Nicholas" };
alert(Object.isExtensible(person)); //true
alert(Object.isSealed(person)); //false
Object.seal(person);
alert(Object.isExtensible(person)); //false
alert(Object.isSealed(person)); //true
person.age = 29;
alert(person.age); //undefined
delete person.name; // 不能删除
alert(person.name); //"Nicholas"
什么是冻结对象?它有哪些特性?
冻结的对象既不可扩展,又是密封的,而且对象数据属性的 [[Writable]] 特性会被设置为 false 。如果定义 [[Set]] 函数,访问器属性仍然是可写的。
var person = { name: "Nicholas" };
alert(Object.isExtensible(person)); //true
alert(Object.isSealed(person)); //false
alert(Object.isFrozen(person)); //false
Object.freeze(person);
alert(Object.isExtensible(person)); //false
alert(Object.isSealed(person)); //true
alert(Object.isFrozen(person)); //true
person.age = 29;
alert(person.age); //undefined
delete person.name; // 删除失败
alert(person.name); //"Nicholas"
person.name = "Greg"; // 写入失败
alert(person.name); //"Nicholas"
JavaScript中的定时器是基于线程实现的吗?
JavaScript 是运行于单线程的环境中的,而定时器仅仅只是计划代码在未来的某个时间执行。执行时机是不能保证的,因为在页面的生命周期中,不同时间可能有其他代码在控制 JavaScript 进程。在页面下载完后的代码运行、事件处理程序、Ajax 回调函数都必须使用同样的线程来执行。实际上,浏览器负责进行排序,指派某段代码在某个时间点运行的优先级。
除了主 JavaScript 执行进程外,还有一个需要在进程下一次空闲时执行的代码队列。随着页面在其生命周期中的推移,代码会按照执行顺序添加入队列。例如,当某个按钮被按下时,它的事件处理程序代码就会被添加到队列中,并在下一个可能的时间里执行。当接收到某个 Ajax 响应时,回调函数的代码会被添加到队列。在 JavaScript 中没有任何代码是立刻执行的,但一旦进程空闲则尽快执行。
定时器对队列的工作方式是,当特定时间过去后将代码插入。注意,给队列添加代码并不意味着对它立刻执行,而只能表示它会尽快执行。设定一个 150ms 后执行的定时器不代表到了 150ms代码就立刻执行,它表示代码会在 150ms 后被加入到队列中。如果在这个时间点上,队列中没有其他东西,那么这段代码就会被执行,表面上看上去好像代码就在精确指定的时间点上执行了。其他情况下,代码可能明显地等待更长时间才执行。
关于定时器要记住的最重要的事情是,指定的时间间隔表示何时将定时器的代码添加到队列,而不是何时实际执行代码。队列中所有的代码都要等到 JavaScript 进程空闲之后才能执行,而不管它们是如何添加到队列中的。
使用 setInterval() 创建的定时器确保了定时器代码规则地插入队列中。这个方式的问题在于,定时器代码可能在代码再次被添加到队列之前还没有完成执行,结果导致定时器代码连续运行好几次,而之间没有任何停顿。幸好,JavaScript 引擎够聪明,能避免这个问题。当使用 setInterval() 时,仅当没有该定时器的任何其他代码实例时,才将定时器代码添加到队列中。这确保了定时器代码加入到队列中的最小时间间隔为指定间隔。这种重复定时器的规则有两个问题:(1) 某些间隔会被跳过;(2) 多个定时器的代码执行之间的间隔可能会比预期的小。假设,某个 onclick 事件处理程序使用 setInterval() 设置了一个 200ms 间隔的重复定时器。如果事件处理程序花了 300ms多一点的时间完成,同时定时器代码也花了差不多的时间,就会同时出现跳过间隔且连续运行定时器代码的情况。
什么是Yielding Processes?
运行在浏览器中的 JavaScript 都被分配了一个确定数量的资源。不同于桌面应用往往能够随意控制他们要的内存大小和处理器时间,JavaScript 被严格限制了,以防止恶意的 Web 程序员把用户的计算机搞挂了。其中一个限制是长时间运行脚本的制约,如果代码运行超过特定的时间或者特定语句数量就不让它继续执行。一旦某个函数需要花 50ms 以上的时间完成,那么最好看看能否将任务分割为一系列可以使用定时器的小任务。脚本长时间运行的问题通常是由两个原因之一造成的:过长的、过深嵌套的函数调用或者是进行大量处理的循环。这两者中,后者是较为容易解决的问题。长时间运行的循环通常遵循以下模式:
for (var i=0, len=data.length; i < len; i++){
process(data[i]);
}
在展开该循环之前,你需要回答以下两个重要的问题。 1.该处理是否必须同步完成?如果这个数据的处理会造成其他运行的阻塞,那么最好不要改动它。不过,如果你对这个问题的回答确定为“否”,那么将某些处理推迟到以后是个不错的备选项。 2.数据是否必须按顺序完成?通常,数组只是对项目的组合和迭代的一种简便的方法而无所谓顺序。如果项目的顺序不是非常重要,那么可能可以将某些处理推迟到以后。 当你发现某个循环占用了大量时间,同时对于上述两个问题,你的回答都是“否”,那么你就可以使用定时器分割这个循环。这是一种叫做数组分块(array chunking)的技术,小块小块地处理数组,通常每次一小块。基本的思路是为要处理的项目创建一个队列,然后使用定时器取出下一个要处理的项目进行处理,接着再设置另一个定时器。基本的模式如下。
function chunk(array, process, context){
setTimeout(function(){
var item = array.shift();
process.call(context, item);
if (array.length > 0){
setTimeout(arguments.callee, 100);
}
}, 100);
}
什么是函数节流?它通常应用在什么场景中?
函数节流背后的基本思想是指,某些代码不可以在没有间断的情况连续重复执行。第一次调用函数,创建一个定时器,在指定的时间间隔之后运行代码。当第二次调用该函数时,它会清除前一次的定时器并设置另一个。如果前一个定时器已经执行过了,这个操作就没有任何意义。然而,如果前一个定时器尚未执行,其实就是将其替换为一个新的定时器。目的是只有在执行函数的请求停止了一段时间之后才执行。以下是该模式的基本形式:
var processor = {
timeoutId: null,
//实际进行处理的方法
performProcessing: function(){
//实际执行的代码
},
//初始处理调用的方法
process: function(){
clearTimeout(this.timeoutId);
var that = this;
this.timeoutId = setTimeout(function(){
that.performProcessing();
}, 100);
}
};
//尝试开始执行
processor.process();
时间间隔设为了 100ms,这表示最后一次调用 process() 之后至少 100ms 后才会调用 performProcessing() 。所以如果 100ms之内调用了 process() 共 20 次, performanceProcessing() 仍只会被调用一次。 这个模式可以使用 throttle() 函数来简化,这个函数可以自动进行定时器的设置和清除,如下例所示:
实现1:
function throttle(method, context) {
clearTimeout(method.tId);
method.tId= setTimeout(function(){
method.call(context);
}, 100);
}
实现2:
// 限频,每delay的时间执行一次
function throttle(fn, delay, ctx) {
let isAvail = true
return function() {
let args = arguments
// 开关打开时,执行任务
if (isAvail) {
fn.apply(ctx, args)
isAvail = false
// delay时间之后,任务开关打开
setTimeout(function() {
isAvail = true
}, delay)
}
}
}
节流在 resize 事件中是最常用的。 例如,假设有一个 <div/> 元素需要保持它的高度始终等同于宽度。那么实现这一功能的 JavaScript 可以如下编写:
window.onresize = function(){
var div = document.getElementById("myDiv");
div.style.height = div. offsetWidth + "px";
};
这段非常简单的例子有两个问题可能会造成浏览器运行缓慢。首先,要计算 offsetWidth 属性,如果该元素或者页面上其他元素有非常复杂的 CSS 样式,那么这个过程将会很复杂。其次,设置某个元素的高度需要对页面进行回流来令改动生效。如果页面有很多元素同时应用了相当数量的 CSS 的话,这又需要很多计算。这就可以用到 throttle() 函数,如下例所示:
function resizeDiv(){
var div = document.getElementById("myDiv");
div.style.height = div.offsetWidth + "px";
}
window.onresize = function(){
throttle(resizeDiv);
};
只要代码是周期性执行的,都应该使用节流,但是你不能控制请求执行的速率。这里展示的throttle() 函数用了 100ms 作为间隔,你当然可以根据你的需要来修改它。
如何实现自定义事件管理框架?
自定义事件背后的概念是创建一个管理事件的对象,让其他对象监听那些事件。实现此功能的基本模式可以如下定义:
function EventTarget(){
this.handlers = {};
}
EventTarget.prototype = {
constructor: EventTarget,
addHandler: function(type, handler){
if (typeof this.handlers[type] == "undefined"){
this.handlers[type] = [];
}
this.handlers[type].push(handler);
},
fire: function(event){
if (!event.target){
event.target = this;
}
if (this.handlers[event.type] instanceof Array){
var handlers = this.handlers[event.type];
for (var i=0, len=handlers.length; i < len; i++){
handlers[i](event);
}
}
},
removeHandler: function(type, handler){
if (this.handlers[type] instanceof Array){
var handlers = this.handlers[type];
for (var i=0, len=handlers.length; i < len; i++){
if (handlers[i] === handler){
break;
}
}
handlers.splice(i, 1);
}
}
};
function handleMessage(event){
alert("Message received: " + event.message);
}
//创建一个新对象
var target = new EventTarget();
//添加一个事件处理程序
target.addHandler("message", handleMessage);
//触发事件
target.fire({ type: "message", message: "Hello world!"});
//删除事件处理程序
target.removeHandler("message", handleMessage);
//再次,应没有处理程序
target.fire({ type: "message", message: "Hello world!"});
ES6新语法
常量
const FLAG = true;
var FLAG = false; //错误!
块级作用域 使用 let 定义的变量在定义它的代码块之外没有定义
for (let i=0; i < 10; i++) {
//执行某些操作
}
alert(i); // 错误!变量 i
剩余参数
Harmony 中不再有 arguments 对象。
function sum(num1, num2, ...nums){
var result = num1 + num2;
for (let i=0, len=nums.length; i < len; i++){
result += nums[i];
}
return result;
}
var result = sum(1, 2, 3, 4, 5, 6);
即使并没有多余的参数传入函数,剩余参数对象也是 Array的实例。
分布参数 通过分布参数,可以向函数中传入一个数组,然后数组中的元素会映射到函数的每个参数上。分布参数的语法形式与剩余参数的语法相同,就是在值的前面加三个点。唯一的区别是分布参数在调用函数的时候使用,而剩余参数在定义函数的时候使用。比如,我们可以不给 sum() 函数一个一个地传入参数,而是传入分布参数:
var result = sum(...[1, 2, 3, 4, 5, 6]);
在这里,我们将一个数组作为分布参数传给了 sum() 函数。以上代码在功能上与下面这行代码等价:
var result = sum.apply(this, [1, 2, 3, 4, 5, 6]);
默认参数值
function sum(num1, num2=0){
return num1 + num2;
}
var result1 = sum(5);
var result2 = sum(5, 5);
生成器 所谓生成器,其实就是一个对象,它每次能生成一系列值中的一个。对于使用 yield 操作符返回值的函数,调用它 时就会创建并返回一个新的 Generator 实例。然后,在这个实例上调用 next() 方法就能取得生成器的第一个值。此时,执行的是原来的函数,但执行流到 yield 语句就会停止,只返回特定的值。从这个角度看, yield 与 return 很相似。如果再次调用 next() 方法,原来函数中位于 yield 语句后的代码会继续执行,直到再次遇见 yield 语句时停止执行,此时再返回一个新值。
function myNumbers(){
for (var i=0; i < 10; i++){
yield i * 2;
}
}
var generator = myNumbers();
try {
while(true){
document.write(generator.next() + "<br />");
}
} catch(ex){
//有意没有写代码
} finally {
generator.close();
}
迭代器
var person = {
name: "Nicholas",
age: 29
};
var iterator = new Iterator(person);
try {
while(true){
let value = iterator.next();
document.write(value.join(":") + "<br>");
}
} catch(ex){
//有意没有写代码
}
数组领悟 所谓数组领悟(array comprehensions),指的是用一组符合某个条件的值来初始化数组。Harmony定义的这项功能借鉴了 Python 中流行的一个语言结构。JavaScript 中数组领悟的基本形式如下:
array = [ value for each (variable in values) condition ];
//原始数组
var numbers = [0,1,2,3,4,5,6,7,8,9,10];
//把所有元素复制到新数组
var duplicate = [i for each (i in numbers)];
//只把偶数复制到新数组
var evens = [i for each (i in numbers) if (i % 2 == 0)];
//把每个数乘以 2 后的结果放到新数组中
var doubled = [i*2 for each (i in numbers)];
//把每个奇数乘以 3 后的结果放到新数组中
var tripledOdds = [i*3 for each (i in numbers) if (i % 2 > 0)];
解构赋值 从一组值中挑出一或多个值,然后把它们分别赋给独立的变量
var [name, value] = ["color", "red"];
alert(name); //"color"
alert(value); //"red"
代理对象 要创建代理对象,可以使用 Proxy.create() 方法,传入一个 handler (处理程序)对象和一个可选的 prototype (原型)对象:
var proxy = Proxy.create(handler);
//创建一个以 myObject 为原型的代理对象
var proxy = Proxy.create(handler, myObject);
要确保代理对象能够按照预期工作,至少要实现以下其中, handler 对象包含用于定义捕捉器(trap)的属性。捕捉器本身是函数,用于处理(捕捉)原生功能,以便该功能能够以另一种方式来处理。要确保代理对象能够按照预期工作,至少要实现以下7 种基本的捕捉器(略)。
代理函数 代理函数与代理对象的区别是它可以执行。要创建代理函数,可以调用 Proxy.createFunction() 方法,传入一个 handler(处理程序)对象、一个调用捕捉器函数和一个可选的构造函数捕捉器函数。例如:
var proxy = Proxy.createFunction(handler, function(){}, function(){});
Map 类型
var map = new Map();
map.set("name", "Nicholas");
map.set("book", "Professional JavaScript");
console.log(map.has("name")); //true
console.log(map.get("name")); //"Nicholas"
map.delete("name");
WeakMap WeakMap 是 ECMAScript 中唯一一个能让你知道什么时候对象已经完全解除引用的类型。 WeakMap与简单映射很相似,也是用来保存键值对儿的。它们的主要区别在于, WeakMap 的键必须是对象,而在对象已经不存在时,相关的键值对儿就会从 WeakMap 中被删除。例如:
var key = {},
map = new WeakMap();
map.set(key, "Hello!");
//解除对键的引用,从而删除该值
key = null;
至于什么情况下适合使用 WeakMap ,目前还不清楚。不过,Java 中倒是有一个相同的数据结构叫 WeakHashMap ;于是,JavaScript 又多了一种数据类型。
StructType
var Size = new StructType({ width: uint32, height: uint32 });
以上代码创建了一个名为 Size 的新结构类型,该类型带有两个属性: width 和 height 。这两个属性都应该保存无符号 32 位整数。 要实例化这个结构类型,需要向构造函数中传入一个带属性值的对象字面量。
var boxSize = new Size({ width: 80, height: 60 });
console.log(boxSize.width); //80
console.log(boxSize.height); //60
ArrayType 通过数组类型( ArrayType )可以创建一个数组,并限制数组的值必须是某种特定的类型
var SizeArray = new ArrayType(Size, 2);
var boxes = new BoxArray([ { width: 80, height: 60 }, { width: 50, height: 50 } ]);
类 JavaScript 中的类只是一种语法糖,覆盖在目前基于构造函数和基于原型的方式和类型之上
class Person {
constructor(name, age){
public name = name;
private age = age;
}
sayName(){
alert(this.name);
}
getOlder(years){
private(this).age += years; // 要访问私有成员,可以使用一种特殊的语法,即调用 private() 函数并传入 this 对象,然后再访问私有成员
}
}
getter 和 setter
class Person {
constructor(name, age){
public name = name;
public age = age;
private innerTitle = "";
get title(){
return innerTitle;
}
set title(value){
innerTitle = value;
}
}
sayName(){
alert(this.name);
}
getOlder(years){
this.age += years;
}
}
继承
class Employee extends Person {
constructor(name, age){
super(name,age);
}
}
模块 模块(或者“命名空间”、“包”)是组织 JavaScript 应用代码的重要方法。每个模块都包含着独立于其他模式的特定、独一无二的功能。模块在其自己的顶级执行环境中运行,因而不会污染导入它的全局执行环境。默认情况下,模块中声明的所有变量、函数、类等都是该模块私有的。对于应该向外部公开的成员,可以在前面加上 export关键字。
module MyModule {
//公开这些成员
export let myobject = {};
export function hello(){ alert("hello"); };
/隐藏这些成员
function goodbye(){
//...
}
}
这个模块公开了一个名为 myobject 的对象和一个名为 hello() 的函数。可以在页面或其他模块中使用这个模块,也可以只导入模块中的一个成员或者两个成员。导入模块要使用 import 命令:
//只导入 myobject
import myobject from MyModule;
console.log(myobject);
//导入所有公开的成员
import * from MyModule;
console.log(myobject);
console.log(hello);
//列出要导入的成员名
import {myobject, hello} from MyModule;
console.log(myobject);
console.log(hello);
//不导入,直接使用模块
console.log(MyModule.myobject);
console.log(MyModule.hello);
在执行环境能够访问到模块的情况下,可以直接调用模块中对外公开的成员。导入操作只不过是把模块中的个别成员拿到当前执行环境中,以便直接操作而不必引用模块。
外部模块 通过提供模块所在外部文件的 URL,也可以动态加载和导入模块。为此,首先要在模块声明后面加上外部文件的 URL,然后再导入模块成员:
module MyModule from "mymodule.js";
import myobject from MyModule;
以上声明会通知 JavaScript 引擎下载 mymodule.js 文件,然后从中加载名为 MyModule 的模块。 请读者注意,这个调用会阻塞进程。换句话说,JavaScript 引擎在下载完外部文件并对其求值之前,不会处理后面的代码。 如果你只想包含模块中对外公开的某些成员,不想把整个模块都加载进来,可以像下面这样使用import 指令:
import myobject from "mymodule.js";
严格模式 ECMAScript 5 最早引入了“严格模式”(strict mode)的概念。通过严格模式,可以在函数内部选择进行较为严格的全局或局部的错误条件检测。使用严格模式的好处是可以提早知道代码中存在的错误,及时捕获一些可能导致编程错误的 ECMAScript 行为。 要选择进入严格模式,可以使用严格模式的编译指示(pragma),实际上就是一个不会赋给任何变量的字符串: “use strict”; 如果是在全局作用域中(函数外部)给出这个编译指示,则整个脚本都将使用严格模式。换句话说,如果把带有这个编译指示的脚本放到其他文件中,则该文件中的 JavaScript 代码也将处于严格模式下。也可以只在函数中打开严格模式,就像下面这样:
function doSomething(){
"use strict";
//其他代码
}
一般来说,非严格模式下会静默失败的情形,在严格模式下就会抛出错误。
ES6与ES5,this的变化比较
参考typescript文档 类类型
js类静态部分与实例部分的区别(参考typescript文档 类类型)
js内存泄漏是怎么产生的?
内存泄漏是因为一块被分配内存既不能被使用,也不能被回收,直到浏览器进程结束。 产生泄漏的原因是闭包维持函数内局部变量,不能被释放,尤其是使用闭包并存在外部引用还setInterval的时候危害很大。 产生泄漏的原因有好几种: (1) 页面元素被删除,但是绑定在该元素上的事件未被删除; (2) 闭包维持函数内局部变量(外部不可控),使其得不到释放; (3) 意外的全局变量; (4) 引用被删除,但是引用内的引用,还存在内存中。 从上述原因上看,内存泄漏产生的根本原因是引用无法正确回收,值类型并不能引发内存泄漏。 对于每个引用,都有自己的引用计数,当引用计数归零或被标记清除时,js垃圾回收器会认为该引用可以回收了。
什么是闭包,跟原型链、作用域链有什么关联
闭包是指存在于一个作用域链分支的函数域内的函数,该函数可以向上逐级访问作用域链上的变量,直到找到为止。当闭包存在外部引用时,js会维持闭包自身以及所在函数作用域链的内存状态。 跟原型链没有什么关联,函数的原型(prototype)主要用于实现继承,原型链可用于追溯继承关系,与作用域链类似,都是向上逐级访问属性,直到被找到,原型链的顶层是null,可以理解为所有的object都继承至null,所以null的类型是object。 作用域链可以看作是一个树形结构,由根节点window向下扩散,下层节点可以访问上层节点,但是上层节点无法访问下层节点,产生闭包的函数作用域属于节点中的一个,向下扩散后闭包函数产生叶子节点,叶子节点之间可以互相访问,当访问的变量在叶子节点中无法找到时,向上层节点查找,直到被找到为止,这个概念有点类似原型链上的属性查找。
npm模块安装机制
安装模块到node_modules目录:
$ npm install <packageName>
更新已安装模块:
$ npm update <packageName>
npm模块仓库提供了一个查询服务,叫做 registry ,以 npmjs.org 提供的仓库为例,它的查询服务网址是 https://registry.npmjs.org/, 在仓库查询地址后面加上模块名称就可以看到仓库中模块的版本信息:
https://registry.npmjs.org/react
其效果等同于以下命令:
$ npm view react
$ npm info react
$ npm show react
$ npm v react
也可以查询模块的指定版本信息:
https://registry.npmjs.org/react/v0.14.6
该版本的压缩包在如下片段中指定:
dist: {
shasum: '2a57c2cf8747b483759ad8de0fa47fb0c5cf5c6a',
tarball: 'http://registry.npmjs.org/react/-/react-0.14.6.tgz'
},
npm install或npm update命令,从 registry 下载压缩包之后,都存放在本地的缓存目录。在 Linux 或 Mac 默认是用户主目录下的.npm目录,在 Windows 默认是%AppData%/npm-cache,可以通过配置查询:
$ npm config get cache
$HOME/.npm
每个模块的每个版本,都有一个自己的子目录,里面是代码的压缩包package.tgz文件,以及一个描述文件package/package.json。 除此之外,还会生成一个{cache}/{hostname}/{path}/.cache.json文件。比如,从 npm 官方仓库下载 react 模块的时候,就会生成registry.npmjs.org/react/.cache.json文件。这个文件保存的是,所有版本的信息,以及该模块最近修改的时间和最新一次请求时服务器返回的 ETag 。对于一些不是很关键的操作(比如npm search或npm view),npm会先查看.cache.json里面的模块最近更新时间,跟当前时间的差距,是不是在可接受的范围之内。如果是的,就不再向远程仓库发出请求,而是直接返回.cache.json的数据。
清空缓存的命令:
$ rm -rf ~/.npm/*
$ npm cache clean
Node模块的安装过程:
- 发出npm install命令
- npm 向 registry 查询模块压缩包的网址
- 下载压缩包,存放在~/.npm目录
- 解压压缩包到当前项目的node_modules目录 一个模块安装以后,本地其实保存了两份。一份是~/.npm目录下的压缩包,另一份是node_modules目录下解压后的代码。但是,运行npm install的时候,默认只会检查node_modules目录,而不会检查~/.npm目录。也就是说,如果一个模块在~/.npm下有压缩包,但是没有安装在node_modules目录中,npm 依然会从远程仓库下载一次新的压缩包。npm 提供了一个–cache-min参数,用于从缓存目录安装模块。
容器的水平居中
div#container {
width:760px;
margin:0 auto;
}
文字的垂直居中
单行文字的垂直居中,只要将行高与容器高设为相等即可。比如,容器中有一行数字。
div#container {
height: 35px;
line-height: 35px;
}
<div id="container">1234567890</div>
如果有n行文字,那么将行高设为容器高度的n分之一即可。
容器的垂直居中
将大容器的定位为relative。将小容器定位为absolute,再将它的左上角沿y轴下移50%,最后将它margin-top上移本身高度的50%即可。
div#big{
position:relative;
height:480px;
}
div#small {
position: absolute;
top: 50%;
height: 240px;
margin-top: -120px;
}
<div id="big">
<div id="small">
</div>
</div>
使用同样的思路,也可以做出水平居中的效果。
图片宽度的自适应
如何使得较大的图片,能够自动适应小容器的宽度:
img {max-width: 100%}
link状态的设置顺序
link的四种状态,需要按照下面的前后顺序进行设置:
a:link
a:visited
a:hover
a:active
用图片充当列表标志
默认情况下,浏览器使用一个黑圆圈作为列表标志,可以用图片取代它:
ul {list-style: none}
ul li {
background-image: url("path-to-your-image");
background-repeat: none;
background-position: 0 0.5em;
}
