- 第1章 历史和标准
- 第2章 基本概念
- 第3章 系统编程概念
- 第4章 文件I/O:通用的I/O模型
- 第5章 深入探究文件I/O
- 第6章 进程
- 第7章 内存分配
- 第8章 用户和组
- 第9章 进程凭证
- 第10章 时间
- 第11章 系统限制和选项
- 第12章 系统和进程信息
- 第13章 文件I/O缓冲
- 第14章 系统编程概念
- 第15章 文件属性
- 第16章 扩展属性
- 第17章 访问控制列表
- 第18章 目录与链接
- 第19章 监控文件事件
- 第20章 信号:基本概念
- 第21章 信号:信号处理器函数
- 第22章 信号:高级特性
- 第23章 定时器与休眠
- 第24章 进程的创建
- 第25章 进程的终止
- 第26章 监控子进程
- 第27章 程序的执行
- 第28章 详述进程创建和程序执行
- 第29章 线程:介绍
- 第30章 线程:线程同步
- 第31章 线程:线程安全和每线程存储
- 第32章 线程:线程取消
- 第33章 线程:更多细节
- 第34章 进程组、会话和作业控制
- 第35章 进程优先级和调度
- 第36章 进程资源
- 第37章 DAEMON
- 第38章 编写安全的特权程序
- 第39章 能力
- 第40章 登录记账
- 第41章 共享库基础
- 第42章 共享库的高级特性
- 第43章 进程间通信简介
- 第44章 管道和FIFO
- 第45章 System V IPC介绍
- 第46章 System V 消息队列
- 第47章 System V 信号量
- 第47章 System V 共享内存
- 第49章 内存映射
- 第50章 虚拟内存操作
- 第51章 POSIX IPC介绍
- 第52章 POSIX 消息队列
- 第53章 POSIX 信号量
- 第54章 POSIX 共享内存
- 第55章 文件加锁
- 第56章 SOCKET:介绍
- 第57章 SOCKET:UNIX DOMAIN
- 第58章 SOCKET:TCP/IP 网络基础
- 第59章 SOCKET:Internet Domain
- 第60章 SOCKET:服务器设计
- 第61章 SOCKET:高级主题
- 第62章 终端
- 第63章 其他备选的I/O模型
- 第64章 伪终端
第1章 历史和标准
1969年贝尔实验室的Ken Thompson在Digital PDP-7小型机上首次实现了UNIX系统。1973年使用C语言对UNIX进行了重写。C语言由贝尔实验室的Dennis Ritchie设计并实现的。
除了遍布于学术界的各种BSD发布版外,到20世纪80年代末商业性质的UNIX实现在各种硬件架构上都有广泛的应用,比如SunOS、Solaris、AIX等等。 每个厂商只生产一种或几种专有的计算机芯片架构,然后再销售运行于该硬件架构之上的专有操作系统。这种专有性意味着消费者转换到另一家专有操作系统和硬件平台的代价十分高昂。具备可移植性的UNIX系统的魅力逐渐开始凸显。
GNU项目(GNU’s not UNIX)的重要成果之一是制定了GNU GPL(通用公共许可协议)。以GPL许可协议发布的软件不但必须开放源码,而且应该能够在GPL条款的约束下自由对其进行重新发布。可以不受限制地修改以GPL许可协议发布的软件,但是任何经修改后发布的软件仍需遵守GPL条款。
2003年12月发布了Linux内核2.6.
C语言标准独立于任何操作系统,即C语言并不依附于UNIX系统。
POSIX是由IEEE指定的标准,符合POSIX.1标准的操作系统应向程序提供调用各项服务的API,POSIX.1文档对此进行了规范。
POSIX 1003.1-2001标准和SUSv3(Single Unix Specification)标准是一回事(大约3700页)。
UNIX标准时间表
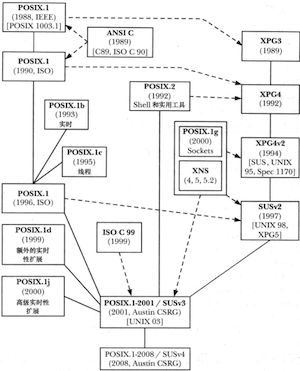
正是由于Linux实际上几近于符合各种UNIX标准,才令其在UNIX市场上如此成功。Linux的实现和发行是分开的,多家组织(商业性的或非商业性的)都握有Linux的发行权。(各家Linux发行商所提供的只是当前稳定内核的快照)
第2章 基本概念
狭义的操作系统(内核)指管理和分配计算机资源(CPU、RAM和设备)的核心层软件。虽然在没有内核的情况下计算机也能够运行程序,但有了内核会极大地简化其他程序的编写和使用。这要归功于内核为管理计算机的有限资源所提供的软件层。
内核的职责
- 进程调度:Linux属于抢占式多任务操作系统,多任务指多个进程(即运行中的程序)可以同时驻留于内存,且都能获得对CPU的使用权。抢占指一组规则,这组规则控制着哪些进程获得对CPU的使用以及能使用多长时间。
- 内存管理:Linux采用了虚拟内存管理机制,该技术主要有2个优势:(1)不同进程之间、进程与内核之间彼此隔离,因此一个进程无法读取或者修改内核或者其他进程的内存内容;(2)只需将进程的一部分保持在内存中,降低了进程对内存的需求量且还能在RAM中同时加载更多的进程(因而使得在任意时刻CPU都能够有至少一个进程可以执行,从而使得对CPU资源的利用更加充分)。
- 提供了文件系统:创建、获取、更新、删除文件;
- 创建和终止进程;
- 对设备的访问:内核既要为程序访问设备提供简化版的标准接口,同时还要仲裁多个进程对同一个设备的访问;
- 联网:内核以用户进程的名义收发网络数据;
- 提供系统调用应用编程接口(API);
- 为每个用户营造一种抽象:虚拟私有计算机;(多用户)
内核态和用户态 现代处理器架构一般允许CPU至少在两种不同状态下运行:用户态、核心态(监管态)。执行硬件指令可使CPU在两种状态间来回切换。与此对应,可将虚拟内存区域划分为用户空间和内核空间部分,在用户态下运行时CPU只能访问用户空间的内存,试图访问内核空间的内存将会引发硬件异常。当运行于内核态时,CPU既能访问用户空间内存,也能访问内核空间内存。仅当处理器在核心态运行时才能执行某些特定操作,比如关闭系统、访问内存管理硬件、IO设备的初始化等等。
信号的传递和进程间通信事件的触发由内核统一协调,对进程而言随时可能发生。进程本身无法创建出新进程,也不能结束自己。进程也不能与计算机外接的输入输出设备直接通信。进程间的所有通信都要通过内核提供的通信机制来完成。
shell是一种具有特殊用户的程序,主要用于读取用户输入的命令,并执行相应的程序以响应命令。对UNIX而言shell只是一个用户进程。bash(Bourne again shell)是由GNU项目对Bourne shell的重新实现,是Linux上应用最广泛的shell。
UNIX内核维护着一套单根目录结构,这与Windows不同,后者的每个磁盘设备都有各自的目录层级。 在目录列表中普通链接是内容为“文件名+指针”的一条记录,而符号链接则是经过特殊标记的文件,内容包含了另一文件的名称。在大多数情况下只要系统调用用到了路径名,内核会自动解除该路径名中符号链接的引用,如果符号链接的目标文件自身是另一个符号链接,那么该解析过程会以递归方式重复下去,不过为了应对可能出现的循环引用,内核对解除引用的次数作了限制。正常链接也称为“硬链接”,符号链接也称为“软链接”。
应该避免以‘-’作为文件名的起始字符,因为一旦在shell命令中使用这种文件名,会被误认为命令选项。
每个进程都有一个当前工作目录,是进程解释相对路径名的参照点。进程的当前工作目录继承自其父进程。用户登录后会依据密码文件中的配置来设置当前工作目录。可以使用cd命令来改变shell的当前工作目录。
也可对目录进程权限设置,但是其意义与普通文件的权限设置不同:
- 读权限允许列出目录内容;
- 写权限允许对目录的内容进行修改(添加、修改、删除文件名)
- 执行权限允许对目录中的文件进行访问(仍需受文件自身访问权限的约束);
UNIX系统I/O模型最为显著的特性之一是其I/O通用性概念,即同一套系统调用(open()、read()等)所执行的I/O操作可施之于所有文件类型。对于应用程序发起的I/O请求内核会将其转化为相应的文件系统或者设备驱动程序操作。 就本质而言内核只提供一种文件类型:字节流序列。 通常由shell启动的进程会继承3个已打开的文件描述符:标准输入、标准输出、标准错误。在交互式shell中上述3者一般都指向终端。
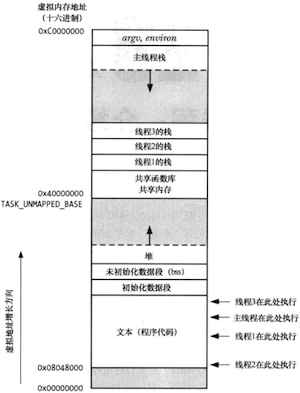
进程的内存布局
- 文本段:程序的指令;
- 数据段:程序使用的静态变量;
- 堆:程序可从该区域动态分配额外内存;
- 栈:随函数调用、返回而增减的一片内存,用于为局部变量和函数调用链接信息分配存储空间;
内核通过对父进程的复制来创建子进程,子进程从父进程处继承数据段、栈、堆的副本后可以修改这些内容而不影响父进程的内容。在内核中文本段被标记为只读,并由父子进程共享。execve()系统调用会销毁现有的文本段、数据段、栈、堆,并根据新程序的代码创建新段来替换它们。
可以使用_exit()系统调用或者向进程传递信号来杀死进程,无论通过何种方式退出,进程都会生成“终止状态”,即一个非负小整数,可供父进程的wait()系统调用检测。惯例是0表示成功,非0表示发生错误。
进程的用户和组标识符
- 真实用户ID和组ID:进程所属的用户和组;
- 有效用户ID和组ID:进程在访问受保护资源时会使用这两个ID来确定访问权限,一般情况下有效ID和相应的真实ID值相同。改变进程的有效ID实际上是一种机制,用来使进程具有其他用户和组的权限;
- 补充组ID:用来标识进程所属的额外组;
特权进程指有效用户ID为0(超级用户)的进程,通常由内核所施加的权限限制对此类进程无效。
init进程 系统启动时内核会创建一个名为init的进程,即所有进程之父,该进程的程序文件为/sbin/init。系统中的所有进程不是由init创建就是由其后代创建。init进程的进程号总是1,且总是以超级用户身份运行。只有关闭系统才能终止该进程。
内存映射 mmap()系统调用会在虚拟地址空间中创建一个新的内存映射。由某一进程所映射的内存可以与其它进程的映射共享,共享实现的方式主要有2种:(1)两个进程都针对某一文件的相同部分加以映射;(2)由fork()创建的子进程从父进程中继承映射。 多个进程共享的内存页面相同时,进程之一对页面的修改其他进程是否可见取决于创建映射时所传入的标志参数。
静态库和共享库 要使用静态库中的函数需要在创建程序的链接命令中指定相应的库,主程序会对静态库中隶属于各目标模块的不同函数加以引用,链接器在解析了引用情况后会从库中抽取所需目标模块的副本将其复制到最终的可执行文件中,即所谓的静态链接。 对于共享库,链接器不会把库中的目标模块复制到可执行文件中,而是在执行文件中写入一条记录以表明可执行文件在运行时需要使用该共享库。一旦在运行时将可执行文件载入内存,动态链接器程序会确保将可执行文件所需的动态库找到。
Linux提供了丰富的进程间通信机制:
- 信号;也称软件中断;
- 管道;
- 套接字;
- 文件锁定;
- 消息队列;
- 信号量;
- 共享内存;
信号从产生直至送达进程期间一直处于挂起状态,系统会在接收进程下次获得调度时将处于挂起状态的信号同时送达。如果接收进程正在运行,则会立即将信号送达。
每个进程都可以执行多个线程,可将线程想象为共享同一虚拟内存及一些其他属性的进程。每个线程都会执行相同的程序代码,共享同一数据区域和堆,不过每个线程都拥有属于自己的栈用来装载本地变量和函数调用调用链接信息。线程之间可以通过共享的全局变量进行通信。显然多线程应用能够从多处理器硬件的并行处理中受益。
shell执行的每个程序都会在一个新进程内发起,比如:
ls -l | sort -k5n | less
如上的shell命令创建了3个进程来执行。
/proc文件系统是一种虚拟文件系统,以文件系统目录和文件形式提供一个指向内核数据结构的接口,为查看和改变各种系统属性提供方便。
第3章 系统编程概念
无论何时,只要执行了系统调用或者库函数,检查调用的返回状态以确定调用是否成功,这是一条编程铁律。
系统调用是受控的内核入口。 系统调用将处理器从用户态切换到和心态,以便CPU访问受到保护的内核内存。 系统调用的组成是固定的,每个系统调用都由一个唯一的数字来标识。
**执行系统调用所发生的步骤
- 1.应用程序通过调用C语言函数库中的wrapper函数来发起系统调用;
- 2.外壳函数将调用参数复制到寄存器;
- 3.外壳函数将系统调用的编号复制到特殊的CPU寄存器(%eax)中,方便内核区分是哪一个系统调用;
- 4.外壳函数执行一条中断机器指令,引发处理器从用户态切换到核心态,并执行系统中断的中断矢量所指向的代码;
- 5.为响应中断内核会调用system_call()例程来处理本次中断,包括检验系统调用编号的有效性、发现并调用相应系统调用的服务例程并获取执行结果、从内核栈中恢复各寄存器值并将系统调用返回值置于栈中、返回至外壳函数同时将处理器切换回用户态;
- 6.若系统调用服务例程的返回值表明调用有误,外壳函数会使用该值来设置全局变量errno,然后外壳函数会返回到调用程序;
系统调用的执行步骤
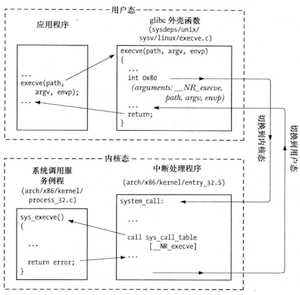
因此从C语言编程的角度来看,调用C语言函数库的外壳函数等同于调用相应的系统调用服务例程。
使用特性测试宏、系统数据类型来处理可移植性问题,略。
与用户空间的函数调用相比哪怕是最简单的系统调用都会产生显著的开销,因为为了执行系统调用系统需要临时性地切换到核心态。此外内核还需要验证系统调用的参数、用户内存和内核内存之间也有数据需要传递。
第4章 文件I/O:通用的I/O模型
文件描述符用于表示所有类型的已经打开的文件,包括管道、FIFO、socket、终端、设备和普通文件。
文件I/O操作的4个主要系统调用:
- fd = open(pathname,flags,mode) // 如果pathname是一个符号链接,会对其进行解引用
- numread = read(fd,buffer,count)
- numwritten = write(fd,buffer,count)
- status = close(fd)
ioctl()系统调用为通用I/O模型之外的专有特性提供了访问接口。
在使用open()系统调用创建新文件时,新建的文件的访问权限不仅仅依赖于参数mode,而且受到进程umask值和(可能存在的)父目录的默认访问控制列表的影响。
一次read()调用所读取的字节数可以小于请求的字节数,对于普通文件而言这有可能是因为当前读取位置靠近文件尾部。当读取的是其他文件类型时,比如管道、socket、终端等,在不同环境下也会出现read()调用读取的字节数小于请求字节数的情况。例如默认情况下从终端读取字符,一旦遇到换行符(\n),read()调用就会结束。
对磁盘文件执行I/O操作时,write()调用成功并不能保证数据已经写入磁盘,因为为了减少磁盘活动量和加快write()系统调用,内核会缓存磁盘的I/O操作。
文件描述符属于有限资源,因此文件描述符关闭失败可能会导致一个进程将文件描述符资源消耗殆尽。
当进程终止时会自动关闭其已打开的所有文件描述符。
对于每个打开的文件,系统内核会记录其当前的文件偏移量,即下一个read()和write()操作的起始位置。
lseek()调用只是调整内核中与文件描述符相关的文件偏移量记录,并没有引起任何对物理设备的访问。
不能将lseek()应用于管道、socket、终端等。
文件空洞 write()函数可以在文件结尾后的任意位置写入数据。从文件结尾后到新写入数据间的这段空间称为文件空洞。从编程角度看文件空洞中是存在字节的,读取空洞将返回以0填充的缓冲区。然而文件空洞不占用任何磁盘空间,直到后续某个时刻在文件空洞中写入了数据,文件系统才会为其分配磁盘块。文件空洞的主要优势在于:与为实际需要的空字节分配磁盘块相比,稀疏填充的文件会占用较少的磁盘空间。 在大多数文件系统中文件的空间是以块为单位进行分配的,块的大小通常为1024字节、2048字节等。如果空洞的边界落在块内,而非恰好落在块边界上,则会分配一个完整的块来存储数据,块中与空洞相关的部分则以空字节填充。 空洞的存在意味着一个文件名义上的大小可能要比其占用的磁盘存储空间要大。向空洞中写入字节,内核需要为其分配存储单元。
第5章 深入探究文件I/O
所有系统调用都是以原子操作方式执行的,其间不会为其他进程或者线程所中断。
多个文件描述符可能指向同一个打开的文件,且这些文件描述符可在相同或者不同的进程中打开。
对于文件描述符与打开的文件之间的关系,内核维护了3个数据结构:
- 进程级的文件描述符表;(进程当前打开的文件描述符)
- 系统级的打开文件表;(当前文件偏移量、打开文件的状态标志、文件访问模式、该文件i-node对象的引用)
- 文件系统的i-node表;(文件类型、文件持有的锁的列表、文件的大小类型等属性)
两个不同的文件描述符若指向同一个打开的文件句柄,将共享同一文件偏移量,即当通过其中一个文件描述符修改了文件的偏移量,从另一个文件描述符中将会观察到这一变化。
文件描述符、打开的文件句柄和i-node之间的关系
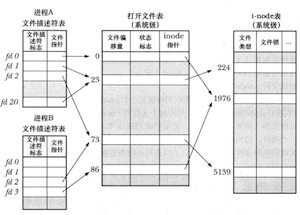
pread()和pwrite()完成与read()、write()相类似的工作,只是前两者会在offset参数指定的位置进行文件I/O操作,而非始于文件的当前偏移量处,且它们不会改变文件的当前偏移量。 当调用pread()和pwrite()时,多个线程可以同时对同一文件描述符执行I/O操作,且不会因为其他线程修改文件偏移量而受到影响。
分散输入和集中输出 readv()和writev()系统调用分别实现了分散输入和集中输出的功能,它们并非只对单个缓冲区进行读写操作,而是一次即可传输多个缓冲区的数据。 readv()从文件描述符中读取一片连续的字节,然后将其散置于一组缓冲区中,最后一个缓冲区中可能只有部分数据。 writev()将一组缓冲区中的所有数据拼接起来,然后以连续的字节序列写入文件描述符指定的文件中。
对于每个进程内核都提供了一个特殊的虚拟目录/dev/fd,该目录包含/dev/fd/n形式的文件名,其中n是进程中打开的文件描述符相对应的编号。例如/dev/fd/0就对应于进程的标准输入。
打开/dev/fd目录中的一个文件等同于复制相应的文件描述符,所以如下两行代码是等价的:
fd = open("/dev/fd/1", O_WRONLY);
fd = dup(1);
/dev/fd实际上是一个符号链接,链接到Linux所专有的/proc/self/fd目录,后者是Linux特有的/proc/PID/fd目录族是
第6章 进程
程序是包含了一系列信息的文件,这些信息描述了如何在运行时创建一个进程,主要包括以下内容:
- 二进制格式标识:用于描述其他可执行文件格式的元信息;
- 机器语言指令:对程序算法进行编码;
- 程序入口地址:标识程序开始执行时的起始指令位置;
- 数据:变量初始值和字面常量;
- 符号表及重定位表:描述程序中函数和变量的位置及名称;
- 共享库和动态链接信息;
进程是由内核定义的抽象实体,并为该实体分配用以执行程序的各项系统资源。从内核角度看,进程由用户内存空间和一系列内核数据结构组成,其中用户内存空间包含了程序代码及代码所使用的变量,而内核数据结构则用于维护进程状态信息。记录在内核数据结构中的信息包括许多与进程相关的标识号、虚拟内存表、打开的文件描述符表、信号传递及处理的有关信息、进程资源使用及限制、当前工作目录和大量的其他信息。
Linux内核限制进程号需小于等于32767,新进程创建时内核会按顺序将下一个可用的进程号分配给其使用,一旦进程号达到32767,会将进程号计数器重置为300,而不是1,因为低数值的进程号为系统进程和守护进程所长期占用,在此范围内搜索尚未使用的进程号是浪费时间。
在Linux 2.6中可以通过修改/proc/sys/kernel/pid_max文件来调整进程号上限。
使用pstree命令可以查看系统当前的进程家族树。
如果子进程的父进程终止,则子进程就会变成孤儿,init进程随即会收养该进程。该子进程随后对getpid()的调用将返回1.
每个进程所分配的内存由很多部分组成,通常称之为段(segment):
- 文本段:程序的机器语言指令,具有只读属性,可以被运行同一程序的所有进程共享;
- 初始化数据段:显式初始化的全局变量和静态变量,当程序加载到内存时从可执行文件中读取这些变量的值;
- 未初始化数据段(BSS段):未进行显式初始化的全局变量和静态变量,程序启动之前系统会将本段内的所有内存初始化为0;
- 栈:是一个动态增长和收缩的段,由栈帧组成,系统会为每个当前调用的函数分配一个栈帧,其中存储了函数的局部变量、实参、返回值;
- 堆:在运行时动态进行内存分配的一块区域;(堆的顶端称为program break)
size命令可以显示二进制可执行文件的文本段、初始换数据段、BSS段的大小。
在Linux/x86-32中典型的进程内存结构:
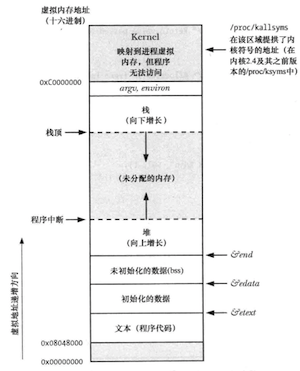
大多数程序都展现了两种类型的局部性:
- 空间局部性:程序倾向于访问在最近访问过的内存地址附近的内存;(指令是顺序执行的,且有时会按顺序处理数据结构)
- 时间局部性:程序倾向于在不久的将来再次访问最近刚访问过的内存地址;(循环)
虚拟内存将每个程序使用的内存切割为小型的、固定大小的页单元,相应地将RAM划分为一系列与虚拟内存页尺寸相同的页帧。任何时刻每个程序仅有部分页需要驻留于物理内存页帧中,这些页构成了所谓的驻留集,程序未使用的页拷贝保存在交换区中(磁盘空间中的保留区域),仅在需要时才会载入物理内存。
内核为每个进程维护一张页表,描述了每页在进程虚拟地址空间中的位置,页表中每个条目要么指出一个虚拟页面再RAM中的位置,要么表明其当前驻留在磁盘上。虚拟内存的实现需要硬件中的分页内存管理单元(PMMU)的支持,PMMU把要访问的每个虚拟内存地址转换为相应的物理内存地址,当特定的虚拟内存地址所对应的页没有驻留于RAM中时,将以页面错误通知内核。
虚拟内存概览
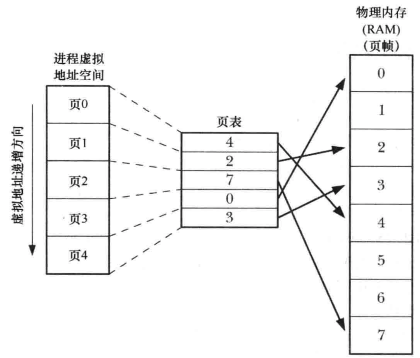
虚拟内存管理使得进程的虚拟地址空间与RAM物理地址空间隔离开来,这带来许多优点:
- 进程与进程、进程与内核相互隔离,一个进程不能读取或修改另一进程或内核的内存;
- 适当情况下不同的进程能够共享内存,比如指向同一程序的不同进程或者使用mmap()显式进行内存共享(内核可以使不同进程的页表条目指向相同的RAM页);
- 便于实现内存保护机制:可以对页表条目进行标记以表示相关页面内容是可读、可写、可执行的;多个进程共享RAM页面时,允许每个进程对内存采取不同的保护措施;
- 程序员和编译器、链接器之类的工具无需关注程序在RAM中的物理布局;
- 因为驻留在内存中的仅是程序的一部分,所以程序的加载和运行都很快,而且一个进程所占用的内存(即虚拟内存大小)能够超出RAM的容量;
- 由于每个进程使用的RAM减少了,RAM中同时可以容纳的进程数量就增多了,这增大了如下事件的概率:任何时刻CPU都至少可以执行一个进程,从而提高CPU的利用率;
专用寄存器“栈指针”用于跟踪当前的栈顶,每次调用函数时会在栈上新分配一帧,每当函数返回时再从栈上将此栈帧移去。
内核栈不同于用户栈(即用户进程虚拟内存空间中的栈),是每个进程保留在内核内存中的内存区域,在执行系统调用的过程中供内核的内部函数调用使用。
每个用户栈帧主要包含如下信息:
- 函数的实参、局部变量,函数在返回时会自动销毁这些变量;
- 函数调用的链接信息:每个函数调用另一个函数时,会在被调用函数的栈帧中保存寄存器的副本,以便函数返回时能够为函数调用者将寄存器恢复原样;
新进程在创建时会继承其父进程的环境副本,这是一种原始的进程间通信的方式。常见的用途是在shell中通过在自身环境中放置变量值,shell可以确保把这些值传递给其所创建的进程,并以此来执行用户命令。此后这个shell所创建的所有子进程都将继承此环境。
可以通过声明main函数的第三个参数来访问环境列表:
int main(int argc, char *argv[], char *envp[])
使用库函数setjmp()和longjmp()可以执行非局部跳转,即跳转的目标为当前执行函数之外的某个位置。(C语言的goto语句不能从当前函数跳到另一个函数,因为编译器无法知道当调用Y时,X函数的栈帧是否在栈上)
优化编译器会重组程序的指令执行顺序,并在CPU的寄存器中,而非RAM中存储某些变量。将变量申明为volatile是告诉优化器不要对其进行优化。
应该尽可能避免使用setjmp()和longjmp()函数。
第7章 内存分配
内核会在进程首次试图访问虚拟内存地址时自动分配新的物理内存页。
通常将堆的当前内存边界称为“program break”,改变堆的大小(分配或者释放内存)其实就像命令内核改变进程的program break位置一样简单。传统的UNIX内核提供了两个操纵program break的系统调用:brk()和sbrk()。
一般情况下free()并不降低program Break的位置,而是将这块内存添加到空闲的内存列表中供后续的malloc()函数循环使用。仅当堆顶空闲内存足够大的时候,free()函数的glibc实现才会调用sbrk()来降低program break的地址。
通常情况下当增大已分配内存时,realloc()会试图去合并在空闲列表中紧随其后且大小满足要求的内存块。若原内存块位于堆的顶部,那么realloc()会对堆进行扩展,如果原内存块位于堆的中部,且紧邻其后的空闲内存空间大小不足,realloc()会分配一块新内存,并将原有数据复制到新内存块中,这将占用大量的CPU资源,一般情况下应该避免使用realloc()。
第8章 用户和组
用户可以隶属于一个或多个组,每个文件都属于某个特定的用户和组,而每个进程也拥有相应的用户ID和组ID,这就决定了进程的所有者以及进程访问文件时所拥有的权限。
系统的每个用户账户都在/etc/passwd文件中有一条记录,例如:
mtk:x:1000:100:Michael Kerrisk:/home/mkt:/bin/bash
7个字段的意义如下:
- 登录名;
- 经过加密的密码;如果启用了shadow密码,系统将不会解析该字段,此时密码字段通常显示为字母x;
- 用户ID;
- 组ID;用户属组中首选组的ID;
- 注释;
- 主目录;用户登录后的初始路径,会用该字段来设置HOME环境变量;
- 登录shell;一旦用户登录,便交由该程序控制,并用该字段设置SHELL环境变量;
之所以设计/etc/shadow文件,其理念是用户的所有非敏感信息存放于人人可读的密码文件中(/etc/passwd),而经过加密处理的密码则由shadow密码文件单独维护,仅供具有特权的程序读取。
对用户所属组的定义由两部分组成(历史原因):
- 密码文件中相应用户记录的组ID字段;
- 组文件(/etc/group)列出的用户所属各组; 当今的UNIX系统已经很少使用组密码。
UNIX系统采用单向加密算法对密码进行加密,加密算法封装于crypt()函数中(DES算法的变体)。
读取密码的程序在读取后应该立即加密密码,并尽快将密码的明文从内存中抹去,以杜绝恶意程序借程序崩溃之机读取内核转储文件以获取密码。此外,如果包含密码的虚拟内存页执行了换出操作,那么特权级程序就能从交换文件中读取密码。另外,拥有足够权限的进程可以通过读取/dev/mem(虚拟设备之一,将计算机物理内存表示为有序字节流)来尝试发现密码。
第9章 进程凭证
实际用户ID和实际组ID确定了进程所属的用户和组。 当进程尝试执行各种操作(即系统调用)时,将结合有效用户ID、有效组ID,连同辅助组ID一起来确定授予进程的权限。 有效用户ID为0的进程拥有超级用户的所有权限,这样的进程也称为特权级进程。某些系统调用只能由特权级进程执行。 通常有效ID与实际ID相等,可以通过系统调用或者执行set-user-ID、set-group-ID程序来修改。
set-user-ID程序会将进程的有效用户ID设置为可执行文件的属主用户ID,从而获得常规情况下并不具有的权限。区别于一般文件,可执行文件还拥有两个特别的权限位set-user-ID位和set-group-ID位,当设置了这两个位时,相应的文件权限位显示为s:
$ su
Password:
# ls -l prog
-rwxr-xr-x 1 root root ...
# chmod u+s prog
# chmod g+s prog
# ls -l prog
-rwsr-sr-x 1 root root ...
saved set-user-ID和saved set-group-ID意在与set-user-ID和set-group-ID程序结合使用,当执行程序时将会发生如下事件:
- 若可执行文件的set-user-ID权限位已开启,则将进程的有效用户ID设置为可执行文件的属主,若未设置,则进程的有效用户ID将不变。
- saved set-user-ID和saved set-group-ID的值由对应的有效ID复制而来,无论正在执行的文件是否设置了set-user-ID和set-group-ID权限位,这一复制都将进行。有不少系统调用允许将set-user-ID程序的有效用户ID在实际用户ID和saved set-user-ID之间切换。这样对于与执行文件用户相关的任何权限程序都能够收放自如。
在Linux系统中要进行诸如打开文件、改变文件属主、修改文件权限之类的文件系统操作时,决定其操作权限的是文件系统用户ID和组ID,而不是有效用户ID和组ID。通常文件系统用户ID和组ID的值等同于相应的有效用户或组ID(跟随其变化而变化),只有当使用Linux特有的两个系统调用setfsuid()和setfsgid()时,才会制造出文件系统ID与相应有效ID的不同。 从严格意义上讲,保留文件系统ID特性已无必要。
辅助组ID用于标识进程所属的若干附加的组,新进程从其父进程处继承这些ID,登录shell从系统组文件中获取其辅助的组ID。将这些ID与有效ID以及文件系统ID相结合就能决定对文件、System V IPC对象和其他系统资源的访问权限。
可以利用Linux系统特有的proc/PID/status文件,通过对其中Uid、Gid等信息的检查来获取任何进程的凭证。
当非特权进程调用setuid()时,仅能修改进程的有效用户ID,而且仅能将有效用户ID修改成相应的实际用户ID或saved set-user-ID。一旦特权进程修改了其ID,那么所有特权都将丢失,且之后不能再使用setuid()将有效用户ID重置为0。
有效用户ID为0的进程属于特权级进程,对该进程发起的各种系统调用可免于接受通常所要经历的诸多权限检查。
第10章 时间
1970年零点,UNIX系统问世的大致时间。 I18N即internationalization,即I加上18个字母再加上N。
当在程序中指定要使用的地区时,实际上是指定了/usr/share/locale下某个子目录的名称。地区设置将影响众多GNU/Linux实用程序,以及glibc的许多函数的功能。
Linux/x86-32以每2000秒变化1秒的频率调整时钟。
事件相关的各种系统调用的精度受限于系统软件时钟(software clock)的分辨率,其度量单位为jiffiles,是定义在内核源码中的常量,也是CPU分配进程时间的单位。Linux/x86-32的软件时钟速度已经达到1000HZ,但是并非可以任意提高时钟频率,因为每个时钟中断会消耗少量CPU时间,这部分时间CPU无法执行任何操作。
进程时间是进程创建后使用的CPU时间数量,内核把CPU时间分为两部分:
- 用户CPU时间是在用户模式下执行所花费的时间数量,对于进程来说是它已经得到的CPU时间;
- 系统CPU时间是在内核模式中执行所花费的时间数量,是内核用于执行系统调用或代表程序执行其他任务的时间;
在执行shell程序时加上time命令,将获得这两个部分的时间:
$ time ./myprog real 0m4.84s user 0m1.030s sys 0m3.43s
第11章 系统限制和选项
系统的限制和选项有可能不同,取决于具体的UNIX实现、特定的运行环境、文件系统等。
系统限制的最小值定义在
SUSv3限制 略。
在shell中可以使用getconf命令来获取特定的限制的值。
SUSv3要求,针对特定限制,调用sysconf()系统调用所获取的值在调用进程的生命周期内应该保持不变。
第12章 系统和进程信息
为了提供更为简便的方法来访问内核信息,许多现代UNIX实现都提供了一个/proc虚拟文件系统,其中包含了用于展示各类内核信息的文件,并允许进程通过常规文件I/O系统调用来方便地读取,甚至修改、之所以将/proc文件系统称为虚拟,是因为其包含的文件和子目录并未存储于磁盘上,而是由内核在进程访问此类信息时动态地创建而成。
/proc/PID目录下的主要文件:
- cmdline 以\0分隔的命令行参数
- cwd 指向当前工作目录的符号链接
- Environ NAME=value键值对组成的环境列表
- exe 指向正在执行的文件的符号链接
- fd 文件目录,包含了指向由进程打开的文件的符号列表
- maps 内存映射
- mem 进程虚拟内存
- mounts 进程的安装点
- root 指向根目录的符号链接
- status 各种进程信息,PID、凭证、内存使用量、信号等等
- task 为进程中的每个线程均包含一个子目录,如/proc/PID/task/TID
为了方便起见,任何进程都可以使用符号链接/proc/self来访问自己的/proc/PID目录。
/proc目录下文件和子目录的节选
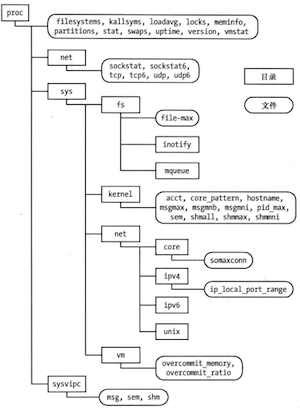
除了/proc/PID子目录中的文件,/proc目录的其他大多数文件都属于root用户,只有root用户能够修改那些可修改的文件。
第13章 文件I/O缓冲
read()和write()系统调用在操作磁盘文件时不会直接发起磁盘访问,而是仅仅在用户空间缓冲区与内核缓冲区高速缓存之间复制数据。例如:
write(fd,"abc",3);
write()随即返回。在后续的某个时刻内核会将其缓冲区中的数据写入(刷新至)磁盘,因此可以说系统调用与磁盘操作并不同步。如果在此期间另一进程试图读取文件的这几个字节,内核将自动从缓冲区高速缓存中提供这些数据,而不是从文件中(读取过期的内容)。
总之,如果与文件发生大量的数据传输,通过采用大块空间缓冲数据,以及执行更少的系统调用,可以极大地提高I/O性能。(同样是往磁盘写入1000个字节,每次写1个字节肯定不如一次写1000个字节)
使用stdio库可以使编程者免于自行处理对数据的缓冲,无论是调用write()来输出还是调用read()来输入。
可以通过调用setvbuf()时设置mode为_IONBF从而实现不对I/O进行缓冲,stderr默认属于这一类型。
若内容发生变化的内核缓冲区在30秒内未经显式方式同步到磁盘上,则一条长期运行的内核线程会确保将其刷新到磁盘上,这一做法是为了规避缓冲区与相关磁盘文件内容长期处于不一致状态。在Linux2.6中该任务由pdflush内核线程执行。
I/O缓冲小结
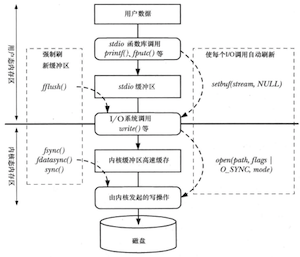
Linux允许应用程序在执行磁盘I/O时绕过缓冲区高速缓存,从用户空间直接将数据传递到文件或者磁盘设备,称为直接I/O或者裸I/O。对于大多数应用而言,使用直接I/O可能会大大降低性能。直接I/O只适用于有特定I/O需求的应用,例如数据库系统,其高速缓存和I/O优化机制均自成一体,无需内核消耗CPU时间和内存去完成相同任务。
第14章 系统编程概念
在内核中每种设备类型都有与之相对应的设备驱动程序,用来处理设备的所有I/O请求。每个设备驱动程序所提供的接口一致,从而隐藏了每个设备在操作方面的差异,满足了I/O操作的通用性。
可将设备划分为以下两种类型:
- 字符设备:基于每个字符来处理数据,终端和键盘都属于字符型设备;
- 块设备:每次处理一块数据,块的大小取决于设备类型,但通常为512字节的倍数。磁盘和磁带设备都属于块设备。
每个设备文件都有主、辅ID号各一,主ID号标识一般的设备等级,内核会使用主ID号查找与该类设备相应的驱动程序,辅ID号能够在一般等级中唯一标识特定设备。设备文件的i-node节点中记录了设备文件的主、辅ID,每个设备驱动程序都会将自己与特定主设备号的关联关系向内核注册,从而建立设备专用文件与设备驱动程序之间的关系(内核是不会使用设备文件名来查找驱动程序的)。
文件系统是对常规文件和目录的组织集合,Linux的强项之一便是支持种类繁多的文件系统。
磁盘分区和文件系统布局
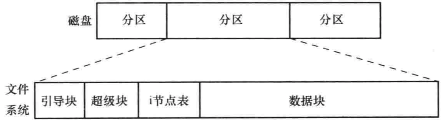
文件系统由以下几部分组成:
- 引导块:不为文件系统所用,只是包含用来引导操作系统的信息;
- 超级块:包含与文件系统有关的参数信息,比如i节点表容量、文件系统中逻辑块的大小等等;
- i节点表:同一文件系统中的每个文件或目录在i节点表中都对应着唯一一条记录,登记了有关文件的各种信息;
- 数据块:文件系统的大部分空间都用于存放数据,以构成驻留于文件系统之上的文件和目录; 驻留于同一物理设备上的不同文件系统,其类型、大小及参数设置都可以有所不同,这也是将一块磁盘划分为多个分区的原因之一。
文件的i节点所维护的信息如下:
- 文件类型(常规文件、目录、符号链接、字符设备等);
- 文件属主;
- 文件属组;
- 3类用户的访问权限;
- 3个时间戳(最后访问时间、最后修改时间、文件状态的最后改变时间);
- 指向文件的硬链接数量;
- 文件的大小,以字节为单位;
- 实际分配给文件的块数量,这一数字可能不会简单等同于文件的字节大小(考虑文件中包含空洞的情形);
- 指向文件数据块的指针;
类似于大多数UNIX文件系统,ext2文件系统在存储文件时数据块不一定连续,甚至不一定按顺序存放。为了定位文件数据块,内核在i节点内维护一组指针。
ext2文件系统中文件的文件块结构
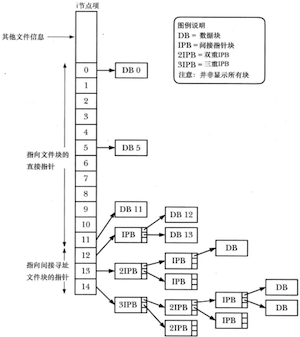 每个i节点包含15个指针,其中前12个指针指向文件前12个块在文件系统中的位置。接下来是一个指向指针块的指针,提供了文件的第13个以及后续数据块的位置。指针块中指针的数量取决于文件系统中块的大小,每个指针需占用4字节因此指针的数量可能在256(块容量1024字节)~1024(块容量4096字节)之间,这样就考虑到了大型文件的情况。即便是对于巨型文件,第14个指针是一个双重间接指针,指向指针块,其块中指针进而指向指针块,此块中指针最终才指向文件的数据块。只要有体量巨大的文件,就会随之产生更深一层的递进。
每个i节点包含15个指针,其中前12个指针指向文件前12个块在文件系统中的位置。接下来是一个指向指针块的指针,提供了文件的第13个以及后续数据块的位置。指针块中指针的数量取决于文件系统中块的大小,每个指针需占用4字节因此指针的数量可能在256(块容量1024字节)~1024(块容量4096字节)之间,这样就考虑到了大型文件的情况。即便是对于巨型文件,第14个指针是一个双重间接指针,指向指针块,其块中指针进而指向指针块,此块中指针最终才指向文件的数据块。只要有体量巨大的文件,就会随之产生更深一层的递进。
这一设计的好处在于:
- 在维持i节点结构大小固定的同时支持任意大小的文件;
- 文件系统可以以不连续方式来存储文件块,又可以通过lseek()随机访问文件,而内核只需计算所要遵循的指针;
- 对于在大多数系统中占绝对多数的小文件而言,这种设计满足了对文件数据块的快速访问(通过i节点的直接指针访问);
- 文件可以有空洞,只需将i节点和间接指针块中的相应指针打上标记(值0),表明这些指针并未指向实际的磁盘块即可,而无需为文件空洞分配空字节数据块;
虚拟文件系统是一种内核特性,通过为文件系统操作创建抽象层来屏蔽不同文件系统的差异。
对于ext2文件系统,在系统崩溃后为确保文件系统的完整性,重启时必须对文件系统的一致性进行检查,这将遍历整个文件系统。采用日志文件系统则无需在系统崩溃后对文件进行漫长的一致性检查。日志文件系统能够确保总是将文件元数据事务作为一个完整单元来提交。系统崩溃之后,即使是超大型的日志文件系统通常也会在几秒之内复原。其缺陷在于增加了文件的更新时间。某些日志文件系统只会确保文件元数据的一致性,由于不记录文件数据,因此一旦系统崩溃可能造成数据丢失。
无法卸载正在使用中的文件系统,即这一文件系统上有文件被打开,或者进程的当前工作目录驻留在此文件系统下。
可以将一个文件系统挂载于文件系统内的多个位置,由于每个挂载点下的目录子树内容都相同,在一个挂载点下对目录子树所做的修改同样可见诸于其他挂载点。Linux允许针对同一挂载点执行多次挂载,每次新挂载都会隐藏之前可见于挂载点下的目录子树。卸载最后一次挂载时,挂载点下上次挂载的内容会再次显示。
Linux同样支持驻留于内存中的虚拟文件系统,比如tmpfs。该文件系统不但使用RAM,而且在RAM耗尽的情况下还会利用交换空间。一旦卸载tmpfs文件系统,或者遭遇系统崩溃,那么该文件系统中的所有数据都将丢失。
许多原生UNIX和Linux文件系统都支持为超级用户预留一部分文件系统块,这样即便在文件系统空间耗尽的情况下,超级用户仍可以登录系统解决故障。
设备都由/dev下的文件来表示,既可以是实际存在的,也可以是虚拟的。
第15章 文件属性
利用系统调用stat()可以获取与文件有关的信息,其中大部分提取自文件的i节点。
chmod命令将会更新文件的上次修改时间,cat命令将会更新文件的上次访问时间。
要执行脚本文件需要同时具备读权限和执行权限。
目录的权限含义:
- 可读:可列出目录下的内容;
- 可写:可在目录内创建、删除文件;(要删除文件,对文件本身无需有任何权限)
- 可执行:可访问目录中的文件; 访问文件时需要拥有对路径名所列所有目录的执行权限,例如想读取/home/mtk/x,则需要拥有对目录/、/home/、/home/mtk的执行权限(还要有对文件x自身的读权限)。若当前工作目录为/home/mtk/sub1,访问相对路径名../sub2/x时,需要有/home/mtk和/home/mtk/sub2这两个目录的可执行权限(不必有对/home的执行权限)。 拥有对目录的读权限,用户只能查看目录中的文件列表,要想访问目录内文件的内容或者是这些文件的i节点信息,还需要有对目录的执行权限。若拥有对目录的可执行权限,而无读权限,只要知道目录内文件的名称,仍可以对其进行访问,但不能列出目录下的内容。
一旦调用open()打开了文件,针对返回描述符的后续系统调用(read()、write()、fstat()、fcntl()、mmap())将不再进行任何权限检查。
检查文件权限时,内核遵循如下的规则:
- 对于特权级进程,授予其所有访问权限;
- 若进程的有效用户ID与文件的用户ID相同,内核会根据文件的属主权限授予进程相应的访问权限;
- 若进程的有效组ID或任一附属组ID与文件的组ID相匹配,内核会根据文件的数组权限授予进程对文件的相应访问权限;
- 若以上三点皆不满足,内核会根据文件的other权限授予进程相应权限; Linux2.6支持访问控制列表,从而可以以每用户或每组为基础来定义文件权限。若文件与一ACL挂钩,内核则会在上述算法的基础上略作改动。
文件模式创建掩码umask是一种进程属性,当进程新建文件或目录时,该属性用于指明应屏蔽哪些权限位。进程的umask通常继承自其父shell,用户可以使用shell的内置命令umask来改变shell进程的umask,从而控制在shell下运行程序的umask。大多数shell的初始化文件会将umask默认设置为022(—-w–w-),即对于同组或其他用户,应该总是屏蔽写权限。
第16章 扩展属性
文件的扩展属性(EA)即以名值对的形式将任意元数据与文件i节点关联起来的技术。可用于实现访问列表和文件能力。EA需要有底层文件系统来提供支撑。 详略。
第17章 访问控制列表
许多UNIX系统对传统的UNIX文件权限模型进行了名为访问控制列表(ACL)的扩展,利用ACL可以在任意数量的用户和组之中为单个用户或组指定文件权限。一个ACL由一系列ACL记录组成,其中每条记录都针对单个用户或用户组定义了对文件的访问权限。 详略。
第18章 目录与链接
目录与普通文件的区别有二:
- 在其i-node条目中会将目录标记为一种不同的文件类型;
- 目录是经特殊组织而成的文件,本质上是一个表格,包含文件名和i-node编号;
以文件/etc/passwd为例展示i-node和目录结构之间的关系
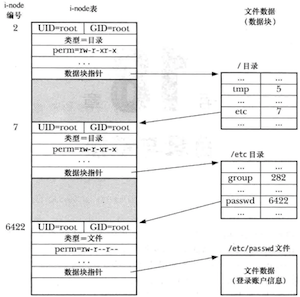 i-node中并没有存储文件名,而是通过目录列表内的一个映射来定义文件名称,好处在于可以在相同或者不同目录中创建多个名称,每个均指向相同的i-node节点,也将这些名称称为硬链接。
i-node中并没有存储文件名,而是通过目录列表内的一个映射来定义文件名称,好处在于可以在相同或者不同目录中创建多个名称,每个均指向相同的i-node节点,也将这些名称称为硬链接。
可以利用ln命令为一个业已存在的文件创建新的硬链接:
$ echo -n 'test,' > abc
$ ls -li abc
122232 -rw-r--r-- 1 mtk users 29 Jun 15 17:07 abc
$ ln abc xyz
$ echo 'ok' >> xyz
$ cat abc
test,ok
$ ls -li abc xyz
122232 -rw-r--r-- 2 mtk users 29 Jun 15 17:07 abc
122232 -rw-r--r-- 2 mtk users 29 Jun 15 17:07 xyz
可见名称abc和xyz指向相同的i-node条目,因此指向相同的文件。其中ls -li展示的第1列为i-node编号,第3列为i-node链接的计数,执行ln操作后计数提升为2。 若移除其中一个文件名,另一个文件名以及文件本身将继续存在:
$ rm abc
$ ls -li xyz
122232 -rw-r--r-- 1 mtk users 29 Jun 15 17:07 xyz
仅当i-node的链接计数降为0时才会删除文件的i-node记录和数据块。 无法通过文件描述符来查找关联的文件名,因为一个文件描述符指向一个i-node,而指向这个i-node的文件名则可能有多个。
对硬链接的限制有二,均可以用符号链接来加以规避:
- 因为目录条目(硬链接)对文件的指代采用了i-node编号,而i-node编号的唯一性仅在一个文件系统之内才能得到保障,所以硬链接必须与其指代的文件驻留在同一文件系统中;
- 不能为目录创建硬链接,从而避免出现另诸多系统程序陷入混乱的链接环路;
符号链接,也称软链接,是一种特殊的文件类型,其数据是另一文件的名称。文件的链接计数中并未将符号链接计算在内,因此如果移除了符号链接所指向的文件名,符号链接本身还将继续存在,尽管无法再对其进行解引用操作,此类链接也称为悬空链接(甚至可以为并不存在的文件名创建一个符号链接)。
对硬链接和符号链接的展现
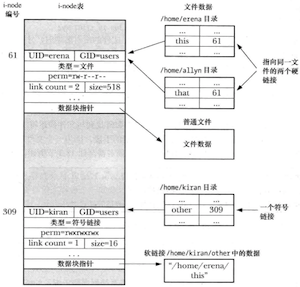
因为符号链接指代一个文件名,而非i-node编号,所以可以用其来链接不同文件系统中的文件。
大部分操作会无视符号链接的所有权和权限,仅当在带有粘性权限位的目录中对符号链接进行移除或改名操作时才会考虑符号链接自身的所有权。
当移除指向文件的最后一个链接时,如果仍有进程持有指代该文件的打开文件描述符,那么在关闭所有此类描述符之前,系统实际上将不会删除该文件。
每个进程都有一个根目录,该目录是解释绝对路径时的起点,默认情况下这是文件系统的真实根目录。特权进程可以通过chroot()系统调用来改变一个进程的根目录,这会将应用程序限定于文件系统的特定区域,因此也称为设立了一个chroot监禁区。ftp程序就是应用chroot()的典型实例:当匿名用户登录ftp时,ftp程序将使用chroot()为新进程设置根目录,即设置为一个专门预留给匿名用户的目录,用户将受困于文件系统中新根目录下的子树中。
并非任何程序都能在chroot监禁区中运行,因为大多数程序与共享库之间采取的是动态链接方式。因此,要么只能局限于运行静态链接程序,要么就在监禁区中复制一套标准的共享库系统目录。
通常最好不要在chroot监禁区文件系统内放置set-user-ID-root程序,此外必须关闭所有指向监禁区外目录的文件描述符(遭到监禁的进程仍然能够利用UNIX套接字来接受另一进程指向监禁区之外目录的文件描述符)。
i-node中并不包含文件的名称,对文件的命名利用的是目录条目,而目录则是列出文件名和i-node编号之间对应关系的一个表格,也将这些目录条目称为硬链接。
符号链接只是一个内容包含了另一个文件名称的文件。
第19章 监控文件事件
自内核2.6.13起,Linux提供inotify机制,以允许应用程序监控文件事件(打开、关闭、创建、删除、修改、重命名等)。关键步骤如下:
- 应用程序使用inotify_init()来创建一个inotify实例,该系统调用返回的文件描述符用于在后续操作中指代该实例;
- 应用程序使用inotify_add_watch()向inotify实例的监控列表添加条目,从而告知内核哪些文件是自己的兴趣所在(通过位掩码的组合来指定关注的事件,比如被访问、被修改等等);
- 为获得事件通知,应用程序需针对inotify文件描述符执行read()操作,每次对read()的成功调用都会返回一个或多个inotify_event结构,其中记录了处于inotify实例监控之下的某一路径名所发生的事件,如果读取时尚未发生任何事件,read()将会阻塞下去,直至有事件产生;
- 应用程序在结束监控时会关闭inotify文件描述符,这将会自动清除与inotify实例相关的所有监控项; inotify机制可用于监控文件或目录,当监控目录时与路径自身及其所包含文件相关的事件都会通知给应用程序。inotify监控机制为非递归,若应用程序有意监控整个目录子树内的事件,则需对该树种的每个目录发起inotify_add_watch()调用。
可以使用select()、poll()、epoll()以及由信号驱动的I/O来监控inotify文件描述符,只要有事件可供读取,上述API就会将inotify文件描述符标记为可读。
第20章 信号:基本概念
信号是事件发生时对进程的通知机制,也称为软件中断。引发内核为进程产生信号的各类事件如下:
- 硬件发生异常:比如执行了异常的机器语言指令、引用了无法访问的内存区域;
- 用户键入了能够产生信号的终端特殊字符,比如Control-C、Control-Z等;
- 发生了软件事件:如针对文件描述符的输出变为有效、调整了终端窗口大小、定时器到期、进程执行的CPU时间超限、某个子进程退出;
针对每个信号都定义了一个唯一的整数,
信号分为两大类:
- 用于内核向进程通知事件,构成所谓的传统或者标准信号,Linux中标准信息范围为1-31;
- 由实时信号构成;
在产生和到达期间,信号处于等待(pending)状态。信号到达后进程视具体信号执行如下可选操作:
- 忽略信息;
- 终止进程;
- 产生核心转储文件,同时进程终止;
- 暂停进程执行;
- 恢复进程执行;
Linux标准信息,略。
信号处理器程序是由程序员编写的函数,用于为响应传递来的信号而执行适当任务。调用信号处理器程序可能会随时打断主程序流程,内核代表进程来调用处理器程序,当处理器返回时,主程序会在处理器打断的位置恢复执行。
为SIGINT信号安装一个处理器程序
#include <signal.h>
#include "tlpi_hdr.h"
static void
sigHandler(int sig)
{
printf("Ouch!\n");
}
int
main(int argc, char *argv[])
{
int j;
if (signal(SIGINT, sigHandler) == SIG_ERR)
errExit("signal");
/* Loop continuously waiting for signals to be delivered */
for (j = 0; ; j++) {
printf("%d\n", j);
sleep(3); /* Loop slowly... */
}
}
现实世界中的应用程序一般不应该在信号处理器程序中使用stdio函数。
与kill命令类似,一个进程能够使用kill()系统调用向另一个进程发送信号。根据其参数pid的不同代表不同的意义,详略。
进程要发送信号给另一个进程,还需要适当的权限:
- 特权级进程可以向任何进程发送信号;
- init进程仅能接收已安装了处理器函数的信号,这样可以防止系统管理员意外杀死init进程;
- 如果发送者的实际或有效用户ID匹配于接受者的实际用户ID或者saved set-user-id,那么非特权进程也可以向另一进程发送信号;
- SIGCONT信号需要特殊处理,物流对用户ID的检查结果如何,非特权进程可以向同一会话中的任何其他进程发送这一信号;
内核会为每个进程维护一个信号掩码,即一组信号,并将阻塞其针对该进程的传递。如果将遭阻塞的信号发送给某进程,那么对该信号的传递将延后,直至从进程信号掩码中移除该信号,从而解除阻塞为止。等待信号集只是一个掩码,仅表明一个信号是否发生,而未表明其发生的次数,所以如果同一个信号在阻塞状态下产生多次,那么会将该信号记录在等待信号集中,并在稍后仅传递一次。
信号是发生某种事件的通知机制,可以由内核、另一进程或者进程自身发送给进程,存在一系列的标准信号类型,每种都有唯一的编号和目的。信号传递通常是异步行为,意味着信号中断进程执行的位置是不可预测的。
第21章 信号:信号处理器函数
一般情况下信号处理器函数应该设计得越简单越好,这将降低引发竞争条件的风险。
无法对信号的产生次数进行可靠计数,在为信号处理器函数编码时需要考虑处理同类信号多次产生的情况。
在信号处理器函数中并非所有系统调用以及库函数都可以安全调用。因为信号处理器函数可能会在任一时间点异步中断程序的执行,从而在同一个进程中实际形成两条(即主程序和信号处理函数)独立(虽然不是并发的)的执行线程。如果同一个进程的多条线程可以同时安全地调用某一函数,那么该函数就是可重入的,安全指无论其他线程调用该函数的执行状态如何,函数均可以产生预期结果。
更新全局变量或者静态数据结构的函数可能是不可重入的。
malloc()函数族以及使用它们的其他库函数都是不可重入的。如果信号处理器函数用到了这类函数,那么将会覆盖主程序中上次调用同一函数所返回的信息。
异步信号安全的函数使指当从信号处理器函数调用时,可以保证其实现是安全的。如果某一个函数是可重入的,又或者信号处理器函数无法将其中断时,就称该函数是异步信号安全的。
对全局变量的读写可能不止一条机器指令,而信号处理器函数就可能会在这些指令序列之间将主程序中断,因此C语言标准以及SUSv3定义了一种整型数据类型sig_atomic_t,意在保证读写操作的原子性。C语言的++和–操作符并不在受保护的范围内。
第22章 信号:高级特性
特定信号(比如Control-\)会引发进程创建一个核心转储文件,并终止运行。核心转储文件是内含进程终止时内存映像的一个文件,将该内存映像加载到调试器中即可以查明信号到达时程序代码和数据的状态。
同步产生的信号会立即传递,例如硬件异常会触发一个即时信号,而当应用程序使用raise()向自身发送信号时,信号会在raise()调用返回前就已经发出。当异步产生一个信号时,即使并未将其阻塞,在信号产生和实际传递之间仍可能会存在一个延迟,在此期间信号处于等待状态。这是因为内核将等待信号传递给进程的时机是该进程正在执行,且发生由内核态到用户态的下一次切换时,即:
- 进程在前度超时后,再度获得调度时(即在一个时间片的开始处);
- 系统调用完成时;
定义于POSIX.1b中的实时信号意在弥补对标准信号的诸多限制,较之于标准信号其优势如下:
- 实时信号的范围更大,可应用于应用程序自定义的目的,而标准信号中可供应用随意使用的信号仅有两个SIGUSR1和SIGUSR2;
- 对实时信号采取的是队列化管理:如果将某一实时信号的多个实例发送给同一进程,那么将会多次传递该信号;
- 当发送一个实时信号时,可为信号指定伴随数据(一个整型或者指针值),供接收进程的信号处理器获取;
- 不同实时信号的传递顺序得到保障;
虽然可将信号视为IPC方式之一,然而信号作为一种IPC机制却饱受限制,因为相对于其他IPC方法,对信号的编程既繁且难(可重入、竞争条件、保证通知不丢失等等)。
第23章 定时器与休眠
Linux中alarm(一次性定时器)和setitimer(间隔式定时器)针对同一进程共享同一实时定时器。
定时器的用途之一是为系统调用的阻塞设定时间上限。
第24章 进程的创建
4个重要的系统调用:
- fork():允许一个进程创建一个新进程,新的子进程几近于对父进程的翻版,子进程将获得父进程的栈、数据段、堆和执行文本段的拷贝;
- exit(status):终止一个进程,将进程占用的资源交还给内核,其参数status为一个整型变量表示进程的退出状态,父进程可以用系统调用wait()来获取该状态;
- wait(&status):如果子进程尚未调用exit()终止,那么wait()会挂起父进程直至子进程终止,子进程的终止状态会通过status参数返回;
- execve(pathname,argv,envp):加载一个新程序到当前进程的内存,这将丢弃现存的程序文本段,并为新程序重新创建栈、数据段以及堆;
概述函数fork()、exit()、wait()、execve()的协同使用
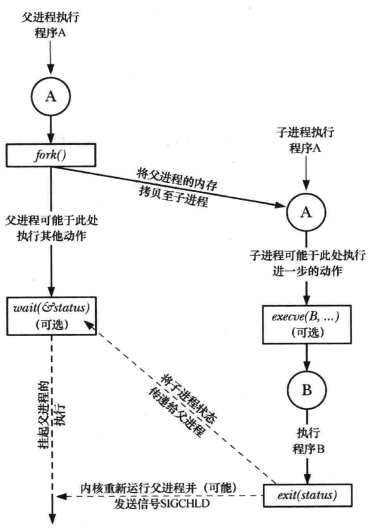
理解fork()的诀窍是要意识到完成对其调用后将存在两个进程,且每个进程都会从fork()的返回处继续执行。这两个进程将执行相同的程序文本段,但却拥有各自的栈段、数据段以及堆段拷贝。程序代码可以通过fork()的返回值来区分父、子进程。调用fork()后系统率先执行哪个进程是无法确定的。
执行fork()时,子进程会获得父进程所有的文件描述符的副本。对于shell来说,shell创建子进程后会调用wait()来暂停运行,并等待子进程退出,只有当执行命令的子进程退出后,shell才会打印自己的提示符。
虽然从概念上可以将fork()理解为对父进程程序段、数据段、堆、栈的拷贝,但实际可能并非这样。因为fork()之后常常伴随着exec(),这将会使用新程序替换进程的代码段并重新初始化其数据段、堆段、栈等。大部分现代UNIX实现采用两种技术来避免这种浪费:
- 内核将每一进程的代码段标记为只读,从而使进程无法修改自身代码,这样父子进程可共享同一代码段;
- 对于父进程数据段、堆段和栈段中的各页,内核采用写时复制技术来处理:最初内核做一些设置令这些段的页表项指向与父进程相同的物理内存页,并将这些页面标记为只读。调用fork()之后,内核会捕获所有父进程或者子进程针对这些页面的修改企图,并为将要修改的页面创建拷贝。系统将新的页面拷贝分配给遭内核捕获的进程,还会对子进程的相应页表做适当调整。
对一共享写时复制页进行修改前后的页表
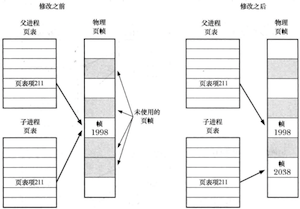
BSD后期版本引入了vfork()系统调用,是为子进程立即执行exec()的程序而专门设计的,其效率远高于fork()。不过现代UNIX采用写时复制技术来实现fork(),因而vfork()实际已无存在的必要。鉴于vfork()的怪异语义可能导致一些难以觉察的程序bug,除非能给性能带来重大提升,否则应当尽量避免使用。
vfork()产生的子进程将使用父进程内存,直至其调用exec()或退出,与此同时将会挂起父进程。
第25章 进程的终止
程序一般不会直接调用系统调用_exit(),而是调用库函数exit(),它会在执行_exit()前执行各种动作:
- 调用退出处理函数(通过atexit()和on_exit()注册的函数),其执行顺序与注册顺序相反;
- 刷新stdio流缓冲区;
- 使用status提供的值执行_exit()系统调用;
程序的另一种终止方法是从main()函数中返回,或者执行到main()函数的结尾处。执行return n等同于执行对exit(n)的调用,因为main()的运行时函数会将main()的返回值作为exit()的参数。
如果程序直接调用_exit()或因信号而异常终止,则不会调用退出处理程序。
通过fork()创建的子进程会继承父进程注册的退出处理函数,而进程调用exec()时,会移除所有已注册的退出处理函数。
在创建子进程的应用中典型的情况下仅有一个进程(一般为父进程)应通过调用exit()终止,而其他进程应通过调用_exit()终止,从而确保只有一个进程调用退出处理程序并刷新stdio缓冲区。
第26章 监控子进程
系统调用wait(status)执行如下动作:
- 如果调用进程并无之前未被等待的子进程终止,调用将一直阻塞,直至某个子进程终止。如果调用时已有子进程终止,wait()则立即返回;
- 如果status非空,那么关于子进程如何终止的信息则会通过status指向的整型变量返回;
- 内核将会为父进程下所有子进程的运行总量追加CPU时间以及资源使用数据;
- 将终止子进程的ID作为wait()的结果返回; 出错时wait()返回-1,可能的错误原因之一是调用进程并无之前被等待的子进程。
wait()存在诸多限制,而设计waitpid()则意在突破这些限制:
- 如果父进程已经创建了多个子进程,使用wait()将无法等待某个特定子进程的完成,只能按顺序等待下一个子进程的终止;
- 如果没有子进程退出,wait()总是保持阻塞状态,有时会希望执行非阻塞的等待,是否有子进程退出立即可知;
- 使用wait()只能发现那些已经终止的子进程,对于子进程因某个信号而停止或是已停止子进程收到SIGCONT信号后恢复执行的情况就无能为力了;
waitid()提供了waitpid()所没有的扩展功能,对于应该等待的子进程事件,waitid()可以更为精确地控制:可通过在options中指定一个或多个标识符来实现这种控制。
wait3()和wait4()执行与waitpid()类似的工作,主要的语义差别在于wait3()和wait4()在参数rusage所指向的结构中返回终止子进程的资源使用情况,包括进程使用的CPU时间总量以及内存管理的统计数据。
父进程与子进程的生命周期一般都不相同,父子进程间互有长短。如果父进程先结束,子进程将变为孤儿进程,并会被init进程接管。如果在父进程wait()之前其子进程就已经终止,系统仍然允许其父进程在之后的某一时刻去执行wait()以确定该子进程是如何终止的:内核通过将该子进程转为僵尸进程来处理这种情况,意味着将释放子进程所把持的大部分资源以供其他进程使用。该进程所唯一保留的是内核进程表中的一条记录,其中记录了子进程的ID、终止状态、资源使用数据等信息。当父进程执行wait()后,由于不再需要子进程所剩余的最后信息,故而内核将删除僵尸进程,如果父进程未执行wait()即退出,那么init进程将接管子进程并自动调用wait(),从而从系统中移除僵尸进程。
父进程应该使用wait()来防止僵尸进程的积累。
如果父进程创建了某一子进程,但并未执行wait(),那么在内核的进程表中将为该子进程永久保留一条记录,如果存在大量此类僵尸进程,它们势必填满内核进程表,从而阻碍新进程的创建。因为僵尸进程无法通过信号杀死,从系统中移除它们的唯一方法就是杀掉它们的父进程,由init进程接管和等待这些僵尸进程,从而清除它们。
无论一个子进程何时终止,系统都会向其父进程发送SIGCHLD信号,对该信号的默认处理是将其忽略,不过也可以安装信号处理程序来捕获并调用wait()来处理僵尸进程。
第27章 程序的执行
调用execve()之后,因为同一进程仍然存在,所以进程ID保持不变。由于是将调用程序取而代之,对execve()的成功调用将永不返回,而且也无需检查execve()的返回值,因为该值肯定为-1.实际上一旦函数返回,就表明发生了错误。
UNIX内核运行解释器脚本的方式与二进制程序无异,前提是脚本必须满足下面两点要求:
- 必须赋予脚本文件可执行权限;
- 文件的起始行必须指定运行脚本解释器的路径名,例如:#! /bin/sh exec()如果检测到传入的文件以#!这两个字节开始,就会析取该行的剩余部分(路径名、参数),并执行解释器程序。
由exec()的调用程序所打开的所有文件描述符在exec()的执行过程中会保持打开状态,且在新程序中依然有效。shell可以利用这一特性为其所执行的程序处理I/O重定向。
第28章 详述进程创建和程序执行
打开进程记账功能后,内核会在每个进程终止时将一条记账信息写入系统级的进程记账文件,这条账单记录包含了内核为该进程所维护的多种信息,包括终止状态以及进程消耗的CPU时间。自内核2.6.10开始,只有当最后一个线程退出时才会为整个进程保存一条账单记录。如果进程的信息并未由其父进程进行监控和报告,那么就可以使用进程记账来获取。
特权进程可以使用系统调用acct()来打开和关闭进程记账功能,应用程序很少使用这一系统调用。
如果系统崩溃,则不会为当前运行的进程记录任何记账信息。
如果开启进程记账特性,且磁盘空闲空间低于low-water百分比,将暂停记账,如果磁盘空间升至low-water之上,则恢复记账。
Linux特有的clone()系统调用也能创建一个新进程,相比于fork(),clone()在进程创建期间对步骤的控制更为精确(通过各种位掩码的组合来指定),clone()主要用于线程库的实现。与fork()不同的是,clone()生成的子进程继续运行时不以调用处为起点,而是调用以参数func所指定的函数。
clone产生的子进程对调用进程的内存既可以获取,也可以共享。但是不能使用父进程的栈,调用者必须为子进程分配一块大小适中的内存空间供子进程的栈使用。
对术语“线程”和“进程”的区分不过是在玩弄文字游戏,实际上线程和进程都是内核调度实体(KSE,kernel scheduling entity),只是与其它KSE之间对属性的共享程度不同(虚拟内存、打开的文件描述符、对信号的处置、进程的ID等)。实际上针对线程间属性共享的方案不少,POSIX线程规范只是其中之一。
POSIX标准规定进程的所有线程共享同一进程ID(即每个线程调用getpid()都应返回相同值),Linux从2.4开始引入了线程组,线程组就是共享同一线程组标识(TGID)的一组KSE,getpid()所返回的就是调用者的TGID,即TGID和进程ID是一回事。
一个线程组内的每个线程都拥有一个唯一的线程标识符用以标识自身,线程可以通过gettid()来获取自己的线程ID。线程ID与进程ID使用相同的数据类型pid_t来表示,线程ID在整个系统中是唯一的,且除了线程担当进程中线程组首线程的情况之外,内核能够保证系统中不会出现线程ID和进程ID相同的情况。
线程组中首个线程的线程ID与线程组ID相同,也将该线程称为线程组首线程。线程组中的所有线程拥有同一个父进程ID,即与线程组首线程ID相同。
如果一个线程组中的任一线程调用了exec(),那么除了首线程之外的其他线程都会终止,新进程将在首线程中执行。
如果线程组中的某个线程调用fork()或vfork()创建了子进程,那么组中的任何线程都可以使用wait()或类似函数来监控该子进程。
容器是轻量级虚拟化的一种形式,将运行于同一内核的进程组从环境上彼此隔离,如同运行在不同的机器上一样。容器可以嵌套,一个容器可以包含另一个容器。为实现容器,内核开发者不得不为内核中的各种全局系统资源提供一个间接层,以便每个容器能够为这些资源提供各自的实例。这些资源包括:进程ID、网络协议栈、uname()返回的ID、用户和组ID命名空间等等。
大体上来说,fork()相当于仅设置了flags为SIGCHID的clone()调用,而vfork()相当于设置了如下flags的clone():
CLONE_VM | CLONE_VFORK | SIGCHLD
第29章 线程:介绍
Pthreads,即POSIX线程。
同一个进程中的多个线程可以并发执行,在多处理器环境下,多个线程可以同时并行。
同时执行4个线程的进程
线程主要是为了解决进程存在的两个问题:
- 进程间的信息难以共享:除去只读代码段外父子进程并未共享内存,因此必须采用一些进程间通信方式在进程间交换信息;
- 调用fork()来创建进程的代价相对较高,即便采用写时复制技术仍然需要复制诸如内存页表和文件描述符表之类的多种进程属性; 创建线程比创建进程通常要快10倍甚至更多,线程的创建之所以较快是因为调用fork()创建子进程时所需复制的诸多属性在线程间本来就是共享的。
启动程序时产生的进程只有单条线程,称之为初始线程或者主线程。主线程执行了return语句(在main函数中),将会导致进程中的所有线程立即终止。
函数pthread_join()等待由thread标识的线程终止,如果线程已经终止,pthread_join()会立即返回。若线程未分离,则必须使用pthread_join()来进行连接,如果未能连接那么线程终止时将产生僵尸线程(与僵尸进程的概念类似)。pthread_join()执行的功能类似于针对进程的waitpid()调用,不过二者之间存在一些显著差别:
- 线程之间的关系是对等的,进程中的任意线程均可以调用pthread_join()与该进程的其他任何线程连接起来。而如果父进程使用fork()创建了子进程,那么它将是唯一能够对子进程调用wait()的进程;
- 无法连接任意线程,也不能以非阻塞方式进行连接;
默认情况下线程是可连接的,即当线程退出时其他线程可以通过调用pthread_join()获取其返回状态。有时候可能不关心线程的返回状态,只是希望系统在线程终止时能够自动清理并移除之,在这种情况下可以调用pthread_detach()并向thread参数传入指定线程的标识符,将该线程标记为处于分离状态。一旦线程处于分离状态,就不能再使用pthread_join()来获取其状态,也无法使其重返可连接状态。
线程相对于进程的优点:
- 线程间的数据共享很简单;
- 创建线程要快于创建进程,线程的上下文切换其消耗时间一般比进程要短;
线程相对于进程的缺点:
- 多线程编程时需要确保调用线程安全的函数,或者以线程安全的方式来调用函数;
- 某个线程中的bug可能会危及该进程的所有线程,因为它们共享着相同的地址空间和属性;
- 每个线程都在争用宿主进程中有限的虚拟地址空间;(每个进程都可以使用全部的有效虚拟内存)
各线程所独有的属性:
- 线程ID;
- 信号掩码;
- 线程持有数据;
- 备选信号栈;
- errno变量;
- 浮点型环境;
- 实时调度策略和优先级;
- CPU亲和力;
- 能力;
- 栈;
第30章 线程:线程同步
互斥量可以帮助线程同步对共享资源的使用,以防止如下情况的发生:线程甲试图访问一共享变量时,线程乙正在对其进行修改。 条件变量是对互斥量的补充,允许线程相互通知共享变量的状态发生了变化。
临界区是指访问某一共享资源的代码片段,并且这段代码的执行应为原子操作,即同时访问同一共享资源的其他线程不应中断该片段的执行。
当超过一个线程加锁同一组互斥量时,就可能发生死锁,要避免此类死锁问题最简单的方法是定义互斥量的层级关系,当多个线程对一组互斥量操作时总是应该以相同的顺序对改组互斥量进行锁定。
条件变量允许一个线程就某个共享变量或其他资源的状态变化通知其他线程,并让其他线程等待(阻塞于)这一通知。即允许一个线程休眠,直至接获另一线程的通知去执行某些操作。条件变量总是和互斥量结合使用,条件变量就共享变量的状态改变发出通知,而互斥量则提供对该共享变量访问的互斥。
条件变量的主要操作是发送信号和等待。发送信号操作即通知一个或多个处于等待状态的线程某个共享变量的状态已经改变。等待操作是指在收到一个通知前一直处于阻塞状态。
第31章 线程:线程安全和每线程存储
若函数可同时供多个线程安全调用,则称之为线程安全函数。导致线程不安全的典型原因是:使用了在所有线程之间共享全局或静态变量。实现函数线程安全最为有效的方式是使其可重入(应以这种方式来实现所有新的函数库)。
线程特有数据、线程局部数据,略。
第32章 线程:线程取消
若将线程的取消性状态和类型分别置为启用和延迟,仅当线程抵达某个取消点时取消请求才会起作用(目标线程如何响应取决于其取消性状态和类型)。
第33章 线程:更多细节
创建线程时每个线程都有一个属于自己的线程栈,且大小固定。32位系统上缺省大小为2MB。
只要有任一线程调用了exec()函数,调用程序将被完全替换,除了调用exec()的线程之外,其他所有线程都将立即消失,没有任何线程会针对线程特有数据执行解构函数,也不会调用清理函数。该进程的所有互斥量和属于进程的条件变量都会消失。
当多线程进程调用fork()时,仅会将发起调用的线程复制到子进程中(子进程中该线程的线程ID和父进程中发起fork()调用线程的线程ID一致),其他线程均在子进程中消失,也不会为这些线程调用清理函数以及针对线程特有数据的解构函数。
线程API的不同实现模型等,详略。
不要将线程与信号混合使用,只要可能应用多线程的程序都应该避免使用信号。
第34章 进程组、会话和作业控制
进程组是一组相关进程的集合,会话是一组相关进程组的集合。 进程组由一个或多个共享同一进程组标识符的进程组成。每个进程组拥有一个首进程,即创建该组的进程,其进程ID为该进程组的ID,新进程会继承其父进程所属的进程组ID。一个进程可能会因为终止而退出进程组,也可能会因为加入了另外一个进程组而退出进程组(进程组首进程无需是最后一个离开进程组的成员)。
会话首进程是创建该新会话的进程,其进程ID会成为会话ID,新进程会继承其父进程的会话ID。一个会话中的所有进程共享单个控制终端,控制终端会在会话首进程首次打开一个终端设备时被建立。一个终端最多可能会成为一个会话的控制终端。在任一时刻会话中的其中一个进程组会成为终端的前台进程组,其他进程组会成为后台进程组。只有前台进程组中的进程才能从控制终端中读取输入。当用户在控制终端中输入一个信号生成终端字符后,该信号会被发送到前台进程组中的所有成员。
会话和进程组的主要用途是用于shell作业控制。如对于交互式登录来讲,控制终端是用户登录的途径。登录shell是会话首进程和终端的控制进程,也是其自身进程组的唯一成员。从shell中发出的每个命令或通过管道连接的一组命令都会导致一个或多个进程的创建,并且shell会把所有这些进程都放在一个新进程组中。当命令或以管道连接的一组命令以&符号结束时,会在后台进程组中运行这些命令,否则就会在前台进程组中运行这些命令。在登录会话中创建的所有进程都会成为该会话的一部分。
进程组具备两个有用的属性:
- 在特定的进程组中父进程能够等待任意子进程;
- 信号能够被发送给进程组中的所有成员;
当一个控制进程失去其终端连接之后,内核会向其发送一个SIGHUP信号来通知它这一事实,这种情况可能会在两种场景中出现:
- 当终端驱动器检测到连接断开后,表明调制解调器或终端上信号的丢失;
- 当工作站上的终端窗口被关闭时; SIGHUP信号的默认处理方式是终止进程。
nohup命令可以用来使一个命令对SIGHUP信号免疫,即将SIGHUP信号的处理设置为SIG_IGN。bash内置的siown命令提供类似的功能。
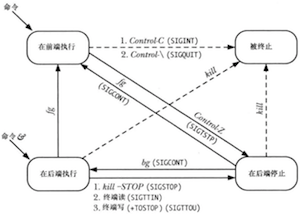
作业控制允许一个shell用户同时执行多个命令,其中一个命令在前台运行,其他命令在后台运行。作业可以被停止和恢复以及在前后台之间移动。
当输入的命令以&符号结束时,该命令会作为后台任务运行。可以使用jobs命令列出所有后台作业。使用fg命令来将后台作业移动到前台。
作业控制状态
第35章 进程优先级和调度
Linux与大多数其他UNIX实现一样,调度进程使用CPU的默认模型是循环时间共享。每个进程轮流使用CPU直至时间片被用光或自己自动放弃CPU(如sleep或者被I/O阻塞)。
进程特性nice值(-20~19)允许进程间接地影响内核的调度算法。非特权进程只能降低自己的优先级,即赋予一个大于默认值0的nice值,这样做之后就对其他进程“友好(nice)”了。给一个进程赋予一个低优先级(即高nice值)并不会导致它完全无法用到CPU,但会导致它使用CPU的时间变少。
为了满足实时进程调度策略,内核必须要提供工具让高优先级进程能快速地取得CPU的控制权,抢占当前运行的所有进程。Linux提供了99个实时优先级。
在循环(SCHED_RR)调度策略中,优先级相同的进程以循环时间分享的方式执行,进程每次使用CPU的时间为一个固定长度的时间片。一旦被调度执行之后,使用SCHED_RR策略的进程会保持对CPU的控制直到下列条件之一得到满足:
- 达到时间片的终点了;
- 自愿放弃CPU(比如执行了阻塞式系统调用);
- 终止了;
- 被一个优先级更高的进程抢占了;
在循环(SCHED_RR)调度策略中当前运行的进程可能会因为如下原因被抢占:
- 之前被阻塞的高优先级进程解除阻塞了;
- 另一个进程的优先级被提到了一个级别高于当前运行进程优先级之上;
- 当前运行的进程的优先级被降低到低于其他进程的优先级;
当一个进程在一个多处理器系统上被重新调度时不一定还在上一次执行的CPU上执行,考虑到CPU高速缓冲器数据的切换,这将对性能有一定的影响。Linux2.6内核尝试了给进程保证软CPU亲和力,即在条件允许的情况下进程重新被调度时将被调度到原来的CPU上运行。
第36章 进程资源
getrusage()允许一个进程监控自己及其子进程已经用掉的资源。getrlimit()/setrlimit()则可以用来修改和获取调用进程对各类资源的消耗限值。
使用shell的内置命令ulimit可以设置shell的资源限制。
第37章 DAEMON
daemon是一种具备下列特征的进程:
- 生命周期很长,通常伴随系统的整个运行过程;
- 在后台运行且不拥有控制终端。由于没有控制终端,因此内核永远不会为daemon自动生成任何任务控制信号以及终端相关的信号,比如SIGHUP等;
常见的daemon进程:cron、sshd、httpd、inetd;(很多daemon程序都以d结尾)
要变成daemon,一个程序需要完成下面的步骤:
- 执行fork(),之后父进程退出,子进程继续执行(使子进程成为init的子进程);之所以需要这样做是因为假设程序是从命令行启动的,父进程终止时会被shell发现,shell在发现之后会显示出另一个shell提示符,并让子进程继续在后台运行;
- 子进程调用setsid()开启一个新会话,并释放它与控制终端之间的所有关联关系;
- 清除进程的umask,以确保当daemon创建文件和目录时拥有所需的权限;
- 修改进程的当前工作目录,一般会改为根目录;
- 关闭daemon从其父进程继承而来的所有打开着的文件描述符;
- 在关闭了文件描述符0、1、2之后,daemon通常会打开/dev/null并使用dup2()使所有这些描述符指向这个设备; /dev/null是一个虚拟设备,会直接丢弃写入的数据。
becomeDaemon()函数用来完成上述步骤以将调用者变成一个daemon。该函数接收一个掩码参数用来有选择地执行其中的步骤。
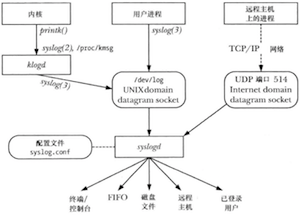
syslog工具提供了一个集中式日志工具,系统中的所有应用程序都可以使用这个工具来记录日志消息。
系统日志概览
第38章 编写安全的特权程序
特权程序能够访问普通用户无法访问的特性和资源,一个程序可以通过下面两种方式以特权方式运行:
- 程序在一个特权用户ID下启动,很多daemon和网络服务器通常以root身份运行,即属于这种类别;
- 程序设置了set-user-ID或set-group-ID权限位,当一个set-user-ID程序被执行后,它会将进程的有效用户ID修改为与程序文件的所有者一样的ID;(尽量避免编写这种程序)
Linux能力模型将传统的all-or-nothing UNIX权限模型划分为一个个被称为能力的单元,一个进程能够独立地启用或禁用单个的能力。通过只启用进程所需的能力使得程序能够在不拥有完整的root权限的情况下运行。
第39章 能力
传统的UNIX权限模型将进程分为两类:能通过所有权限检测的有效用户ID为0的进程和其他所有需要根据用户和组ID进行权限检测的进程。这个模型的粗粒度划分是一个问题,Linux能力模型优化了这个问题。 在大多数时候Linux能力模型对程序员来讲都是不可见的,原因是当一个对能力一无所知的应用程序的有效用户ID为0时,内核会赋予该进程所有能力。
每个进程都拥有3个相关的能力集:
- 许可的:一个进程可能使用的能力;
- 有效的:内核会使用这些能力来对进程执行权限检查;
- 可继承的:当这个进程执行一个程序时可以将这些权限带入许可集中;
实际上能力是一个线程级的特性,进程中的每个线程的能力都可以单独进行调整,在/proc/PID/task/TID/status文件中可以查看一个多线程进程中某个具体线程的能力,/proc/PID/status文件显示了主线程的能力。
第40章 登录记账
登录记账关注的是哪些用户当前登录进了系统,以及记录过去的登录和登出行为:
- utmp文件维护着当前登录进系统的用户记录;
- wtmp文件包含着所有用户登录和登出行为的记录信息以供审计之用;
- lastlog文件记录着每个用户最近一次登录系统的时间,who、last等命令都使用了这些文件中的信息;
第41章 共享库基础
共享库是一种将库函数打包成一个单元使之能够在运行时被多个进程共享的计数。
构建程序的最简单方式是将每一个源文件编译为目标文件,然后将这些目标文件链接在一起组成一个可执行程序:
$ cc -g -c prog.c mod1.c mod2.c mod3.c
$ cc -g -o prog_nolib prog.o mod1.o mod2.o mod3.o
链接由链接器程序ld来完成,当使用gcc时,编译器会在幕后调用ld。
静态库也称为归档文件,是一个保存所有被添加到其中的目标文件的副本的文件,在链接命令行中只需要指定静态库的名称,而无需一个个地列出目标文件,链接器知道如何搜索静态库并将可执行程序需要的对象抽取出来。
共享库的关键思想是目标模块的单个副本由所有需要这些模块的程序共享,目标模块不会被复制到链接过的可执行文件中,相反当第一个需要共享库中的模块的程序启动时,库的单个副本就会在运行时被加载进内存,后面使用同一个共享库的其他程序启动时,会使用已经被加载进内存的库的副本。所以使用共享库意味着可执行程序需要的磁盘空间和虚拟内存更少了。
虽然共享库的代码是由多个进程共享的,但是其中的变量却不是,每个使用库的进程会拥有自己的在库中定义的全局和静态变量的副本。
创建共享库:
$ gcc -g -c -fPIC -Wall mod1.c mod2.c mod3.c
$ gcc -g -shared -o libfoo.o mod1.o mod2.o mod3.o
创建一个共享库并将一个程序与该共享库链接起来
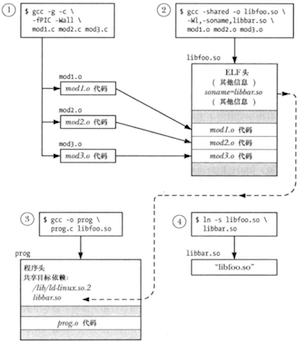
加载共享库的程序的执行
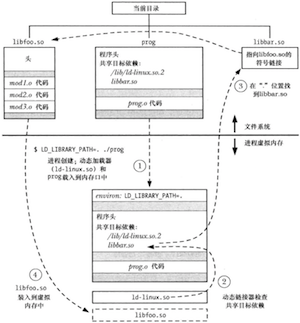
可以通过查看/proc/PID/maps文件来列出进程用到的所有共享库。
ldd命令用于显示一个程序运行所需的所有共享库:
ldd ls
一般共享库及其关联的符号链接会被安装在标准目录中以方便编译器搜索,标准目录包括:
- /usr/lib 大多数标准库安装的目录;
- /lib 应该将系统启动时用到的库安装在这个目录中(因为在系统启动时还没有挂载/usr/lib);
- /usr/local/lib 应该将非标准或实验性的库安装在这个目录;
- 在/etc/ld.so.conf中列出的目录; 搜索的记录会创建缓存,如/etc/ld.so.cache。每当安装了一个新的库,或者更新、删除了已有的库,或者修改了/etc/ld.so.conf文件中的目录列表,都应该运行ldconfig以生成缓存。
在默认情况下当链接器能够选择名称一样的共享库和静态库时,会优先使用共享库。
第42章 共享库的高级特性
dlopen API使得程序能够在运行时打开一个共享库,根据名字在库中搜索一个函数,然后调用这个函数(即延迟加载),在运行时采用这种方式加载的共享库通常称为动态加载的库。
有些时候需要监控动态链接器的操作以弄清它在搜索哪些库,可以通过LD_DEBUG环境变量来完成:通过将这个变量设置为一个或多个关键词可以从动态链接器中得到各种跟踪信息。
$ LD_DEBUG=libs date
第43章 进程间通信简介
UNIX IPC工具分类
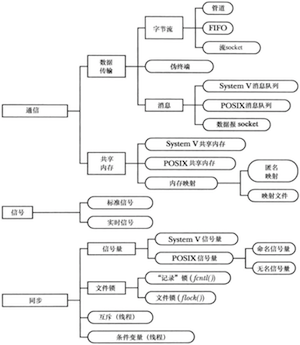
使用管道在两个进程间交换数据
可以将通信工具分为两类:
- 数据传输工具:为了进行通信,一个进程将数据写入到IPC工具中,另一个进程从中读取数据,这些工具要求在用户内存和内核之间进行两次数据传输;
- 共享内存:进程通过将数据放到由进程间共享的一块内存中以完成信息的交换(内核通过将每个进程中的页表条目指向同一个RAM分页来实现这一功能);由于无需系统调用以及用户内存和内核内存之间的数据传输,因此共享内存的速度非常快;
大多数现代UNIX系统都提供了三种形式的共享内存:
- System V共享内存;
- POSIX共享内存;
- 内存映射;
对于共享内存的IPC方式来说,可以通过各种同步方法,比如信号量、文件锁、互斥体和条件变量等,来防止进程执行诸如同时更新一块共享内存或同时更新文件的同一个数据块之类的操作。
在诸多IPC方法中,只有socket允许进程通过网络来进行通信,socket可以用于两个域中:UNIX和Internet。通常将一个使用UNIX socket进行通信的程序转换为一个使用Internet socket进行通信的程序只需要做出微小的改动。
第44章 管道和FIFO
管道是UNIX上最古老的IPC方法:
$ ls | wc -l
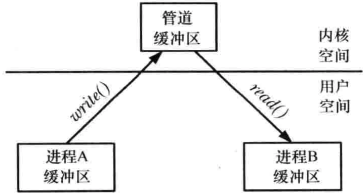
实际上这两个进程并不知道管道的存在,它们只是从标准文件描述符中读取数据和写入数据,shell必须要完成相关的工作。试图从一个当前为空的管道中读取数据将会被阻塞直到至少有一个字节被写入到管道中为止。在管道中数据的传递方向是单向的。
管道其实是在内核内存中维护的缓冲器,这个缓冲器的存储能力是有限的,一旦管道被填满之后,后续向该管道的写入操作就会被阻塞直到读者从管道中移除了一些数据为止。
从语义上来讲,FIFO与管道类似,它们之间最大的差别在于FIFO在文件系统中拥有一个名称,并且其打开方式与打开一个普通文件是一样的。这样就能将FIFO用于非相关进程之间的通信。
可以使用mkfifo命令在shell中创建一个FIFO。一旦FIFO被创建,任何进程都可以打开它,只要它能够通过常规的文件权限检测。
分隔字节流中消息的常用方法
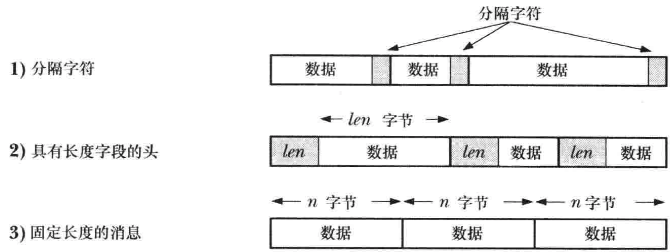
第45章 System V IPC介绍
消息队列、信号量、共享内存。
略。
第46章 System V 消息队列
在客户端-服务器 IPC中使用单个消息队列
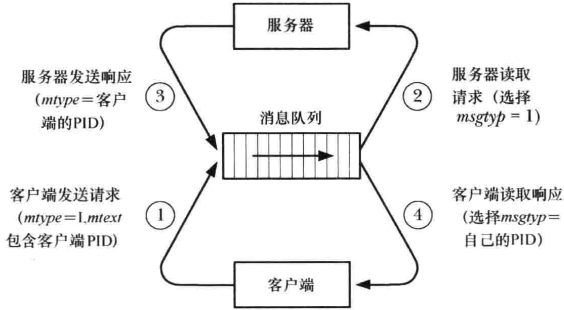
一个客户端使用一个消息队列的客户端-服务器 IPC
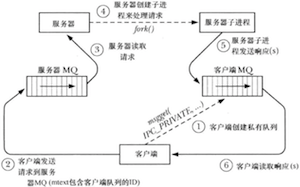
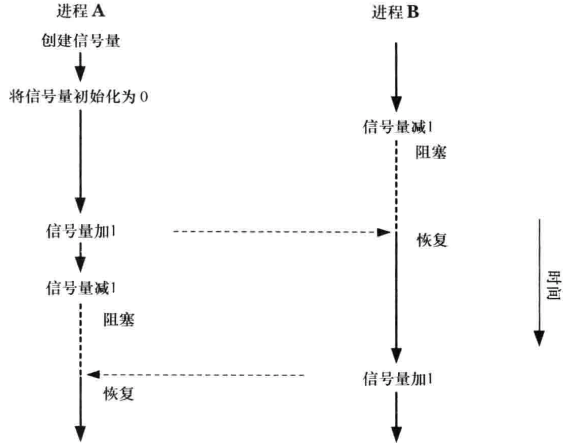
第47章 System V 信号量
信号量不是用来在进程间传输数据的,而是用来同步进程的动作的。一个信号量是一个由内核维护的整数,其值被限制为大于或等于0,在一个信号量上可以执行各种操作:
- 将信号量设置为一个绝对值;
- 在信号量当前值的基础上加上一个数量;
- 在信号量当前值的基础上减去一个数量;(可能导致调用进程阻塞)
- 等待信号量的值等于0;(可能导致调用进程阻塞)
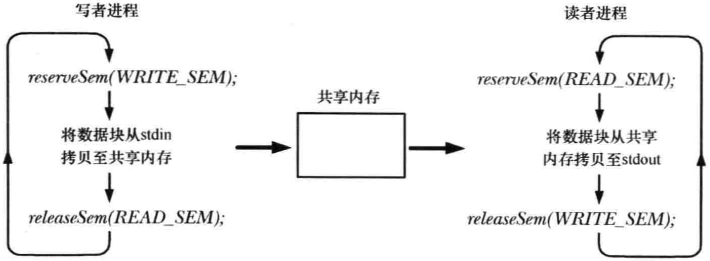
使用信号量同步两个进程
第47章 System V 共享内存
使用信号量确保对共享内存的互斥、交替访问
第49章 内存映射
mmap()系统调用在调用进程的虚拟地址空间中创建一个新的内存映射,映射有两种:
- 文件映射:将一个文件的一部分直接映射到调用进程的虚拟内存中;
- 匿名映射:没有对应的文件,这种映射的分页会被初始化为0;
当两个或者更多个进程共享相同的分页时,每个进程都有可能会看到其他进程对分页内容做出的变更,这取决于映射是私有的还是共享的:
- 私有映射:在映射内容上发生的变更对其他进程不可见,内核使用了写时复制技术来提高性能;
- 共享映射:在映射内容上发生的变更将堆其他进程可见,变更将会发生在底层的文件上;
内存映射I/O所带来的性能优势在大型文件中执行重复随机访问时最有可能体现出来。如果顺序地访问一个文件,并假设执行I/O时使用的缓冲区大小足够大以至于能够避免执行大量的I/O系统调用,那么与read()和write()相比,mmap()带来的性能上的提升就非常有限或者说根本就没有带来性能上的提升。性能提升的幅度之所以非常有限的原因是不管使用何种技术,整个文件的内容在磁盘和内存之间只传输一次,效率的提高主要得益于减少了用户空间和内核空间之间的一次数据传输,并且与磁盘I/O所需的时间相比,内存使用量的降低通常是可以忽略的。
内存本身也有一些开销:映射、分页故障、解除映射、更新硬件内存管理单元的超前转换缓冲区。
内存映射的常见用途:
- 分配进程私有的内存;
- 对一个进程的文本段和初始化数据段中的内容进行初始化;
- 在通过fork()关联起来的进程之间共享内存;
- 执行内存映射I/O,还可以将其与无关进程之间的内存共享结合起来;
第50章 虚拟内存操作
在一些应用程序中将一个进程的虚拟内存的部分或者全部锁进内存以确保它们总是位于物理内存中是非常有用的。对被锁住的分页的访问可以确保永远不会因为分页故障而发生延迟,这对于那些需要确保快速响应时间的应用程序来讲是很有用的。此外也可以防止内存被恶意溢出导致交换行为,从而产生安全问题。
第51章 POSIX IPC介绍
消息队列、信号量、共享内存。 略。
第52章 POSIX 消息队列
第53章 POSIX 信号量
第54章 POSIX 共享内存
略。
第55章 文件加锁
通过检查Linux特有的/proc/locks文件可以看到当前系统中存在的锁。
一些程序,特别是很多daemon,需要确保同一时刻只有一个程序实例在系统上运行,常见的实现方式是让daemon在一个标准目录中创建一个文件,并在该文件上放置一把写锁。/var/run目录通常是存放此类锁文件的位置,通常daemon会把进程ID写入锁文件,因此这个文件在命名时常以.pid为扩展名。
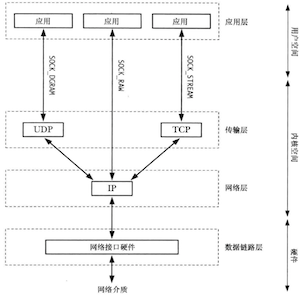
第56章 SOCKET:介绍
socket存在于一个通信domain中,它确定了识别出一个socket的方法,以及socket通信的范围。
现代操作系统至少支持下列domain:
- UNIX(AF_UNIX):在同一台主机上的应用程序之间进行通信;
- IPv4(AF_INET)
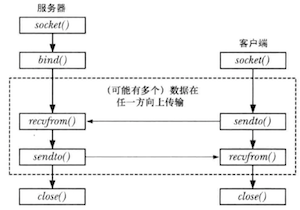
- IPv6(AF_INET6) 每种socket的实现都至少提供了两种socket:流、数据报。流socket提供了一个可靠的双向的字节流通信信道。而数据报socket在使用时无需与另一个socket连接。在Internet Domain中,数据报socket使用了UDP协议,流socket使用了TCP协议。
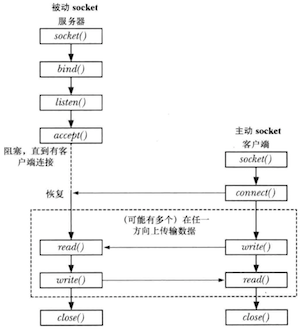
有关socket的几个关键系统调用:
- socket() 创建一个新socket()
- bind() 将一个socket()绑定到一个地址上
- listen() 允许一个流socket接受来自其他socket的接入连接
- accept() 在一个监听流socket上接受来自一个对等应用程序的连接
- connect() 建立与另一个socket之间的连接
理解accept()的关键点是它会创建一个新socket(),并且正是这个新socket()会与执行connect()的对等socket进行连接。
socket I/O可以使用传统的read()和write()系统调用或使用一组socket()特有的系统调用如send()、recv()、sendto()以及recvfrom()来完成。默认情况下,这些系统调用在I/O操作无法被立即完成时会阻塞。
流socket上用到的系统调用
数据报socket上用到的系统调用
第57章 SOCKET:UNIX DOMAIN
在UNIX domain中,socket地址以路径名来表示,但在这些socket上发生的I/O无须对底层设备进行操作。
对于UNIX domain socket来讲,数据报的传输是在内核中发生的,并且也是可靠的。所有消息都会按序被递送并且也不会发生重复的情况。
socket文件的所有权和权限决定了哪些进程能够与这个socket进行通信。
第58章 SOCKET:TCP/IP 网络基础
TCP/IP套件中的协议
SOCKET_RAW允许应用程序直接与IP层进行通信。
第59章 SOCKET:Internet Domain
UNIX domain的数据报socket是可靠的,但UDP socket则是不可靠的:数据报可能会丢失、重复或到达的顺序与被发送的顺序不一致。 在一个UNIX domain数据报socket上发送数据会在接收socket的数据队列满时阻塞,与之不同的是,使用UDP时如果进入的数据报会使接受者的队列溢出,那么数据报就会没静默丢弃。
系统上运行的服务和端口号信息会记录在/etc/services文件中。
之所以要选择使用UNIX domain socket是存在几个原因的:
- 在一些实现上,UNIX domain socket的速度比Internert domain socket的速度快;
- 可以使用目录权限来控制对UNIX domain socket的访问;
- 使用UNIX domain socket可以传递打开的文件描述符和发送者的验证信息;
第60章 SOCKET:服务器设计
使用socket的网络服务器端程序有两种常见的设计方式:
- 迭代型:服务器每次只处理一个客户端,只有当完全处理完一个客户端的请求后才去处理下一个客户端;
- 并发型:能够同时处理多个客户端的请求;
对于负载很高的的服务器来说,为每个客户端创建一个新的子进程(甚至线程)所带来的开销对服务器来说是个沉重的负担,一般会考虑如下设计方案:
- 在服务器上预先创建多个进程或线程;
- 在单个进程中处理多个客户端(需要采用一种能允许单个进程同时监视多个文件描述符上I/O事件的I/O模型);
第61章 SOCKET:高级主题
如果出现了部分I/O现象,即read()返回的字节数少于请求的数量,或者阻塞式的write()调用在完成了部分数据的传输后被信号处理例程中断,那么有时候需要重新调用系统调用来完成全部数据的传输,这可以通过两个系统调用readn()和writen()来实现。
使用close()系统调用会将双向通信信道上的两端都关闭,而使用shutdown()系统调用可以只关闭连接的一端,这样数据只能在一个方向上通过socket传输。
sendfile()系统调用可以绕过用户控件缓冲区,直接发送文件。
TCP报文格式

TCP结点以状态机的方式来建模,状态迁移图如下:
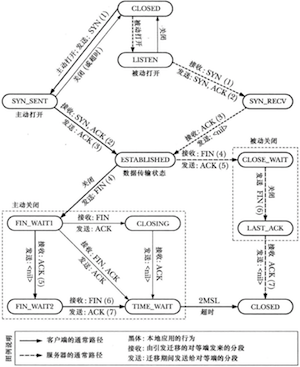
第62章 终端
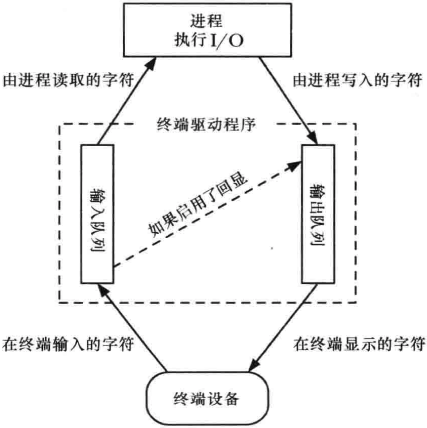
终端设备的输入和输出队列
第63章 其他备选的I/O模型
同时监控多个I/O文件描述符的I/O模型:
- I/O多路复用允许进程同时检查多个文件描述符以找出它们中的任何一个是否可执行I/O操作。系统调用select()和poll()用来执行I/O多路复用。select()和poll()的优势在于可移植性,缺点在于当同时检查大量的文件描述符时性能较低。
- 信号驱动I/O是指当有输入或者数据可以写到指定的文件描述符上时,内核向请求组数据的进程发送一个信号,进程可以处理其他任务,当I/O操作可执行时通过接收信号来获得通知。
- epoll API是Linux专有的特性,拥有较好的性能。 这些操作都不会执行实际的I/O操作,它们只是告诉我们某个文件描述符已经处于就绪状态了,这时需要调用其他的系统调用来完成实际的I/O操作。
一些其他的UNIX实现了类似epoll的机制,比如Solaris提供了特殊的/dev/poll文件,其他一些变种的BSD提供了kqueue API。
Libevent库是这样一个软件层,它提供了检查文件描述符I/O事件的抽象,其底层机制能够以透明的方式应用上述的各种I/O多路复用技术。
详细的比较,略。
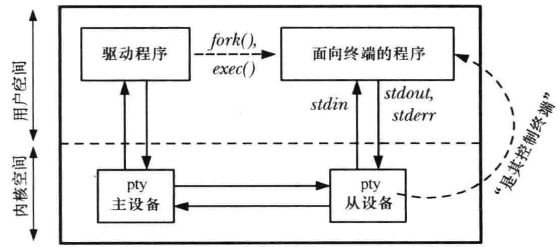
第64章 伪终端
伪终端是一对互联的虚拟设备:主伪终端和从伪终端。伪终端对提供了一条双向IPC通道,从伪终端表现得就像一个标准终端一样,所有可以施加于终端设备的操作同样可以施加于伪终端从设备上。
两个程序通过伪终端通信
ssh使用伪终端的原理
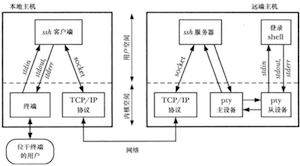
一对伪终端同一个双向管道相似,任何写入到伪终端主设备的数据都会在从设备端作为输入出现,而任何写入到从设备的数据也会在主设备端作为输入出现。
